 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel soups to increase inference without increasing compute time
Paper and Code
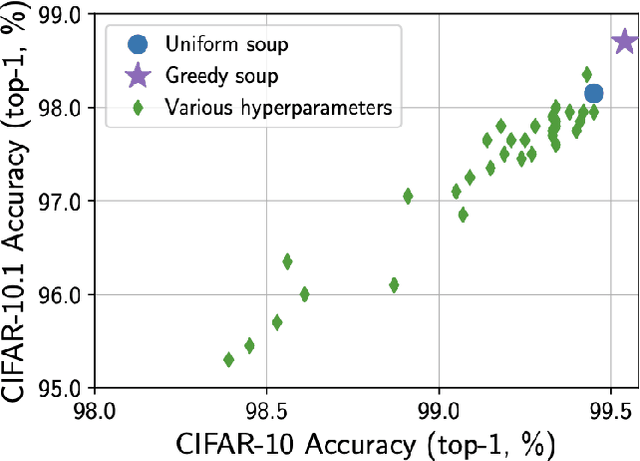


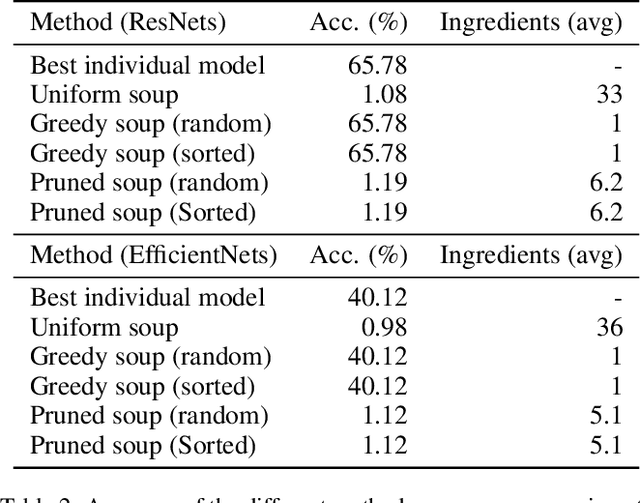
In this paper, we compare Model Soups performances on three different models (ResNet, ViT and EfficientNet) using three Soup Recipes (Greedy Soup Sorted, Greedy Soup Random and Uniform soup) from arXiv:2203.05482, and reproduce the results of the authors. We then introduce a new Soup Recipe called Pruned Soup. Results from the soups were better than the best individual model for the pre-trained vision transformer, but were much worst for the ResNet and the EfficientNet. Our pruned soup performed better than the uniform and greedy soups presented in the original paper. We also discuss the limitations of weight-averaging that were found during the experiments. The code for our model soup library and the experiments with different models can be found here: https://github.com/milo-sobral/ModelSoup