 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-free Reinforcement Learning for Stochastic Stackelberg Security Games
Paper and Code
May 24, 2020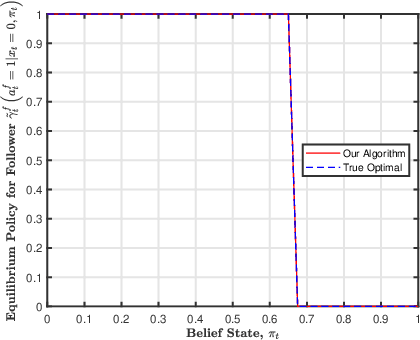
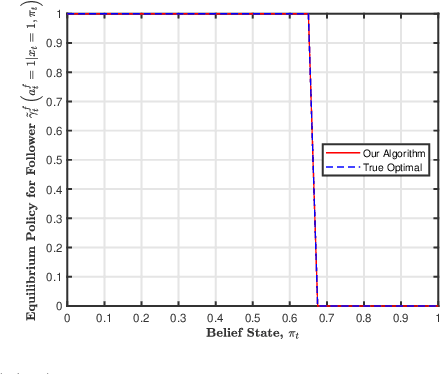
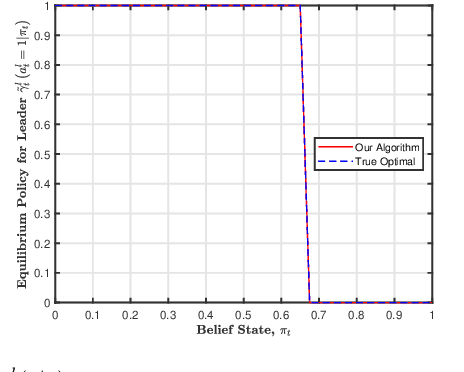
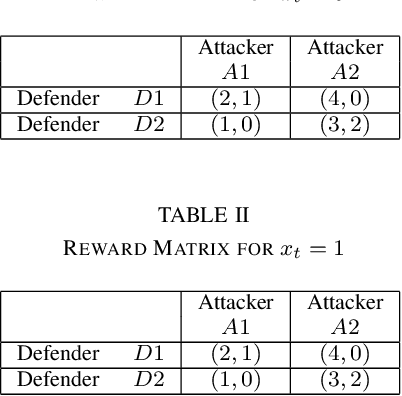
In this paper, we consider a sequential stochastic Stackelberg game with two players, a leader and a follower. The follower has access to the state of the system while the leader does not. Assuming that the players act in their respective best interests, the follower's strategy is to play the best response to the leader's strategy. In such a scenario, the leader has the advantage of committing to a policy which maximizes its own returns given the knowledge that the follower is going to play the best response to its policy. Thus, both players converge to a pair of policies that form the Stackelberg equilibrium of the game. Recently,~[1] provided a sequential decomposition algorithm to compute the Stackelberg equilibrium for such games which allow for the computation of Markovian equilibrium policies in linear time as opposed to double exponential, as before. In this paper, we extend the idea to an MDP whose dynamics are not known to the players, to propose an RL algorithm based on Expected Sarsa that learns the Stackelberg equilibrium policy by simulating a model of the MDP. We use particle filters to estimate the belief update for a common agent which computes the optimal policy based on the information which is common to both the players. We present a security game example to illustrate the policy learned by our algorithm. by simulating a model of the MDP. We use particle filters to estimate the belief update for a common agent which computes the optimal policy based on the information which is common to both the players. We present a security game example to illustrate the policy learned by our algorithm.