 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMKQA: A Linguistically Diverse Benchmark for Multilingual Open Domain Question Answering
Paper and Code



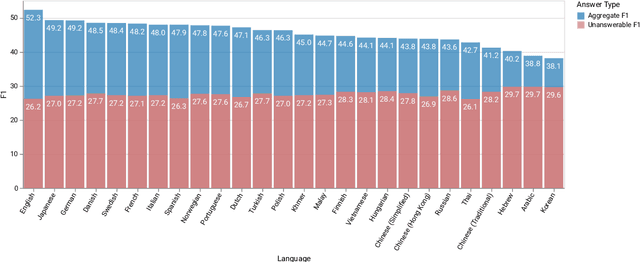
Progress in cross-lingual modeling depends on challenging, realistic, and diverse evaluation sets. We introduce Multilingual Knowledge Questions and Answers (MKQA), an open-domain question answering evaluation set comprising 10k question-answer pairs aligned across 26 typologically diverse languages (260k question-answer pairs in total). The goal of this dataset is to provide a challenging benchmark for question answering quality across a wide set of languages. Answers are based on a language-independent data representation, making results comparable across languages and independent of language-specific passages. With 26 languages, this dataset supplies the widest range of languages to-date for evaluating question answering. We benchmark state-of-the-art extractive question answering baselines, trained on Natural Questions, including Multilingual BERT, and XLM-RoBERTa, in zero shot and translation settings. Results indicate this dataset is challenging, especially in low-resource languages.