 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimizing the Societal Cost of Credit Card Fraud with Limited and Imbalanced Data
Paper and Code
Sep 05, 2019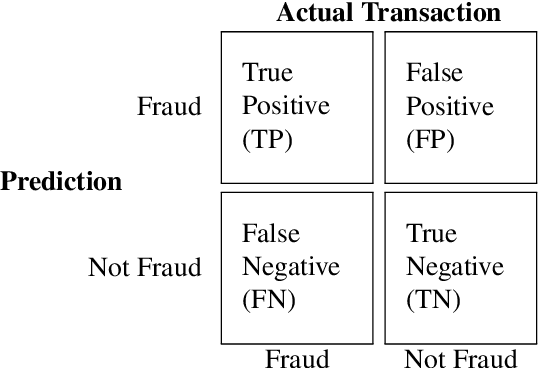

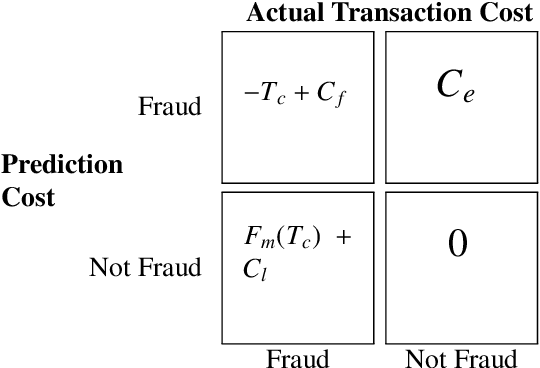

Machine learning has automated much of financial fraud detection, notifying firms of, or even blocking, questionable transactions instantly. However, data imbalance starves traditionally trained models of the content necessary to detect fraud. This study examines three separate factors of credit card fraud detection via machine learning. First, it assesses the potential for different sampling methods, undersampling and Synthetic Minority Oversampling Technique (SMOTE), to improve algorithm performance in data-starved environments. Additionally, five industry-practical machine learning algorithms are evaluated on total fraud cost savings in addition to traditional statistical metrics. Finally, an ensemble of individual models is trained with a genetic algorithm to attempt to generate higher cost efficiency than its components. Monte Carlo performance distributions discerned random undersampling outperformed SMOTE in lowering fraud costs, and that an ensemble was unable to outperform its individual parts. Most notably,the F-1 Score, a traditional metric often used to measure performance with imbalanced data, was uncorrelated with derived cost efficiency. Assuming a realistic cost structure can be derived, cost-based metrics provide an essential supplement to objective statistical evaluation.