 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetrics for saliency map evaluation of deep learning explanation methods
Paper and Code
Jan 31, 2022
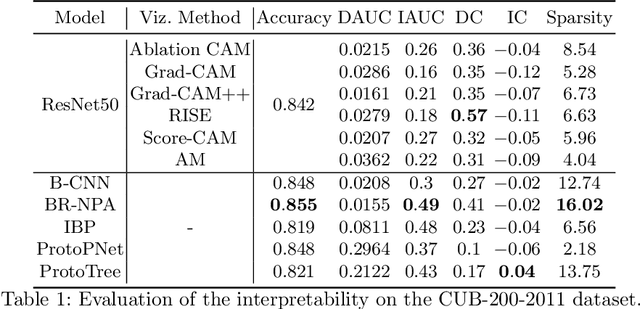


Due to the black-box nature of deep learning models, there is a recent development of solutions for visual explanations of CNNs. Given the high cost of user studies, metrics are necessary to compare and evaluate these different methods. In this paper, we critically analyze the Deletion Area Under Curve (DAUC) and Insertion Area Under Curve (IAUC) metrics proposed by Petsiuk et al. (2018). These metrics were designed to evaluate the faithfulness of saliency maps generated by generic methods such as Grad-CAM or RISE. First, we show that the actual saliency score values given by the saliency map are ignored as only the ranking of the scores is taken into account. This shows that these metrics are insufficient by themselves, as the visual appearance of a saliency map can change significantly without the ranking of the scores being modified. Secondly, we argue that during the computation of DAUC and IAUC, the model is presented with images that are out of the training distribution which might lead to an unreliable behavior of the model being explained. %First, we show that one can drastically change the visual appearance of an explanation map without changing the pixel ranking, i.e. without changing the DAUC and IAUC values. %We argue that DAUC and IAUC only takes into account the scores ranking and ignore the score values. To complement DAUC/IAUC, we propose new metrics that quantify the sparsity and the calibration of explanation methods, two previously unstudied properties. Finally, we give general remarks about the metrics studied in this paper and discuss how to evaluate them in a user study.