 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-learnt priors slow down catastrophic forgetting in neural networks
Paper and Code

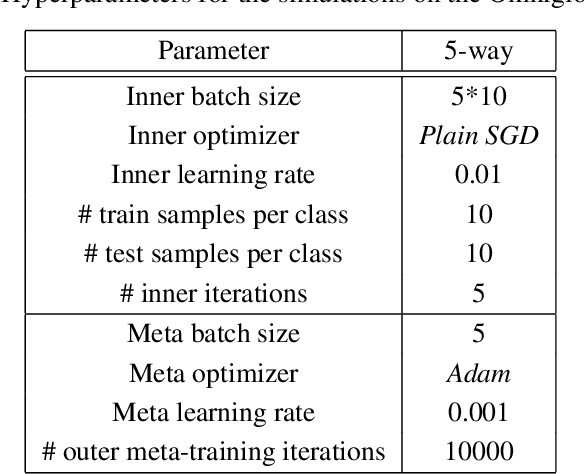


Current training regimes for deep learning usually involve exposure to a single task / dataset at a time. Here we start from the observation that in this context the trained model is not given any knowledge of anything outside its (single) training distribution, and has thus no way to learn parameters (i.e., feature detectors or policies) that could be helpful to solve other tasks, and to limit future interference on the acquired knowledge, and thus catastrophic forgetting. Here we show that catastrophic forgetting can be mitigated in a meta-learning context, by exposing a neural network to multiple tasks in a sequential manner during training. Finally, we present SeqFOMAML, a meta-learning algorithm that implements these principles, and we evaluate it on a sequential learning problem composed by Omniglot classification tasks.