 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMessage Passing Descent for Efficient Machine Learning
Paper and Code
Feb 16, 2021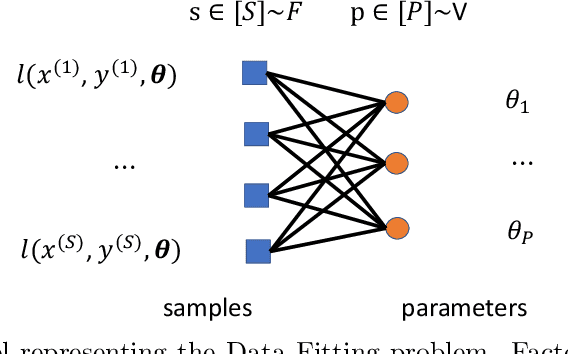
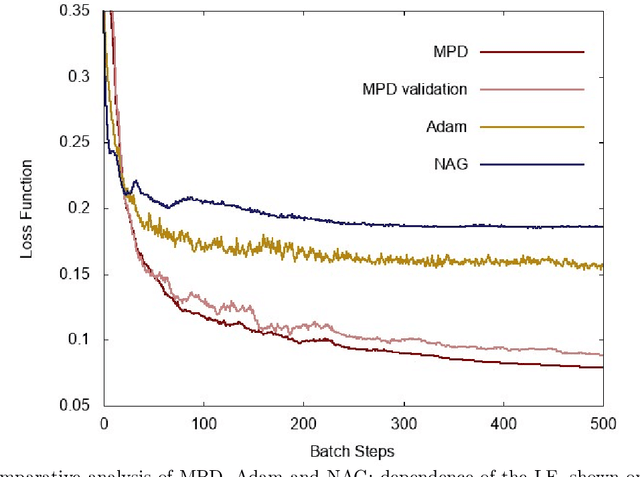
We propose a new iterative optimization method for the {\bf Data-Fitting} (DF) problem in Machine Learning, e.g. Neural Network (NN) training. The approach relies on {\bf Graphical Model} (GM) representation of the DF problem, where variables are fitting parameters and factors are associated with the Input-Output (IO) data. The GM results in the {\bf Belief Propagation} Equations considered in the {\bf Large Deviation Limit} corresponding to the practically important case when the number of the IO samples is much larger than the number of the fitting parameters. We suggest the {\bf Message Passage Descent} algorithm which relies on the piece-wise-polynomial representation of the model DF function. In contrast with the popular gradient descent and related algorithms our MPD algorithm rely on analytic (not automatic) differentiation, while also (and most importantly) it descents through the rugged DF landscape by \emph{making non local updates of the parameters} at each iteration. The non-locality guarantees that the MPD is not trapped in the local-minima, therefore resulting in better performance than locally-updated algorithms of the gradient-descent type. We illustrate superior performance of the algorithm on a Feed-Forward NN with a single hidden layer and a piece-wise-linear activation function.