 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedication Regimen Extraction From Medical Conversations
Paper and Code
Jan 03, 2020

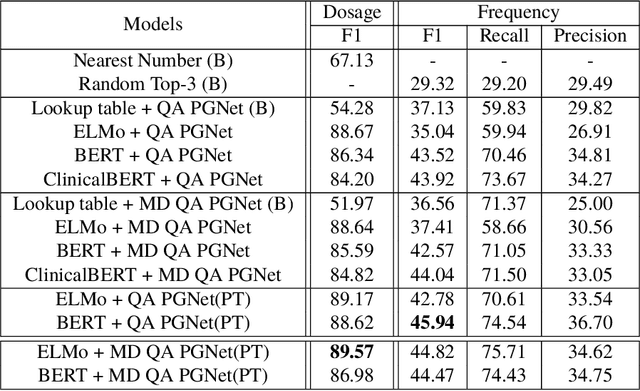
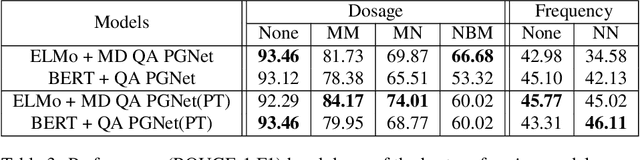
Extracting relevant information from medical conversations and providing it to doctors and patients might help in addressing doctor burnout and patient forgetfulness. In this paper, we focus on extracting the Medication Regimen (dosage and frequency for medications) discussed in a medical conversation. We frame the problem as a Question Answering (QA) task and perform comparative analysis over: a QA approach, a new combined QA and Information Extraction approach, and other baselines. We use a small corpus of 6,692 annotated doctor-patient conversations for the task. Clinical conversation corpora are costly to create, difficult to handle (because of data privacy concerns), and thus scarce. We address this data scarcity challenge through data augmentation methods, using publicly available embeddings and pretrain part of the network on a related task (summarization) to improve the model's performance. Compared to the baseline, our best-performing models improve the dosage and frequency extractions' ROUGE-1 F1 scores from 54.28 and 37.13 to 89.57 and 45.94, respectively. Using our best-performing model, we present the first fully automated system that can extract Medication Regimen tags from spontaneous doctor-patient conversations with about ~71% accuracy.