 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Wikipedia Article Quality in One Dimension by Extending ORES with Ordinal Regression
Paper and Code
Aug 31, 2021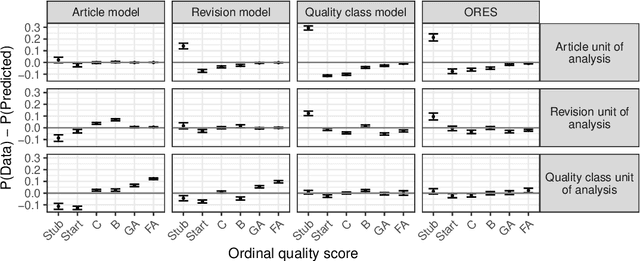
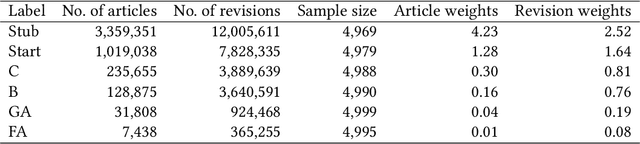
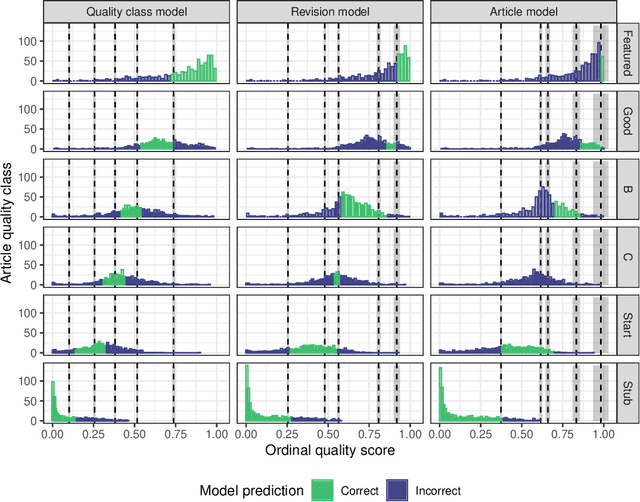
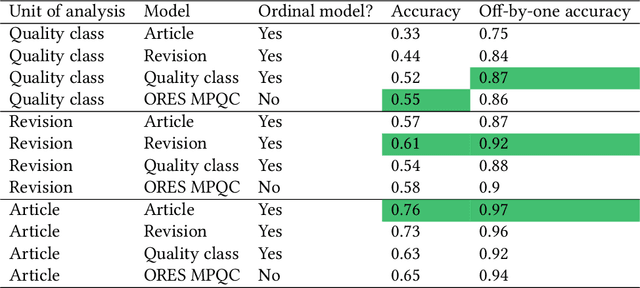
Organizing complex peer production projects and advancing scientific knowledge of open collaboration each depend on the ability to measure quality. Article quality ratings on English language Wikipedia have been widely used by both Wikipedia community members and academic researchers for purposes like tracking knowledge gaps and studying how political polarization shapes collaboration. Even so, measuring quality presents many methodological challenges. The most widely used systems use labels on discrete ordinal scales when assessing quality, but such labels can be inconvenient for statistics and machine learning. Prior work handles this by assuming that different levels of quality are "evenly spaced" from one another. This assumption runs counter to intuitions about the relative degrees of effort needed to raise Wikipedia encyclopedia articles to different quality levels. Furthermore, models from prior work are fit to datasets that oversample high-quality articles. This limits their accuracy for representative samples of articles or revisions. I describe a technique extending the Wikimedia Foundations' ORES article quality model to address these limitations. My method uses weighted ordinal regression models to construct one-dimensional continuous measures of quality. While scores from my technique and from prior approaches are correlated, my approach improves accuracy for research datasets and provides evidence that the "evenly spaced" assumption is unfounded in practice on English Wikipedia. I conclude with recommendations for using quality scores in future research and include the full code, data, and models.