 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring the Impact of Individual Domain Factors in Self-Supervised Pre-Training
Paper and Code
Mar 02, 2022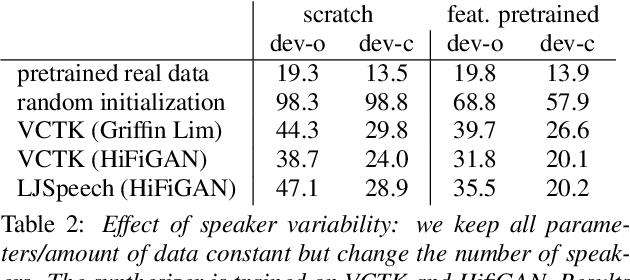
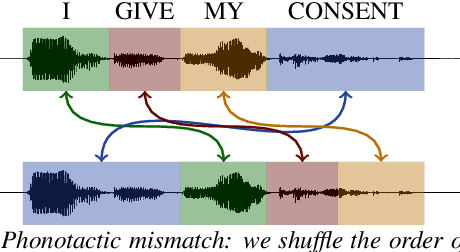
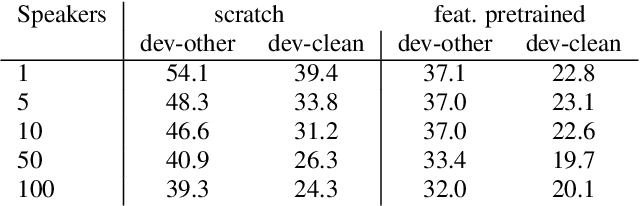

Human speech data comprises a rich set of domain factors such as accent, syntactic and semantic variety, or acoustic environment. Previous work explores the effect of domain mismatch in automatic speech recognition between pre-training and fine-tuning as a whole but does not dissect the contribution of individual factors. In this paper, we present a controlled study to better understand the effect of such factors on the performance of pre-trained representations. To do so, we pre-train models either on modified natural speech or synthesized audio, with a single domain factor modified, and then measure performance on automatic speech recognition after fine tuning. Results show that phonetic domain factors play an important role during pre-training while grammatical and syntactic factors are far less important. To our knowledge, this is the first study to better understand the domain characteristics in self-supervised pre-training for speech.