 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximum Entropy Regularization and Chinese Text Recognition
Paper and Code
Jul 09, 2020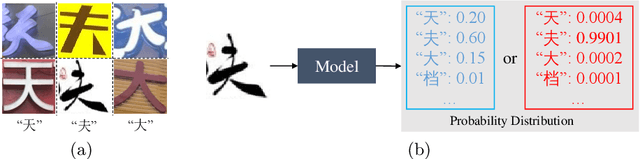

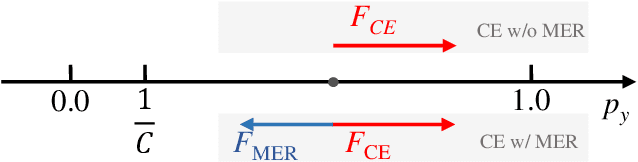

Chinese text recognition is more challenging than Latin text due to the large amount of fine-grained Chinese characters and the great imbalance over classes, which causes a serious overfitting problem. We propose to apply Maximum Entropy Regularization to regularize the training process, which is to simply add a negative entropy term to the canonical cross-entropy loss without any additional parameters and modification of a model. We theoretically give the convergence probability distribution and analyze how the regularization influence the learning process. Experiments on Chinese character recognition, Chinese text line recognition and fine-grained image classification achieve consistent improvement, proving that the regularization is beneficial to generalization and robustness of a recognition model.