 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMASS: Multi-task Anthropomorphic Speech Synthesis Framework
Paper and Code
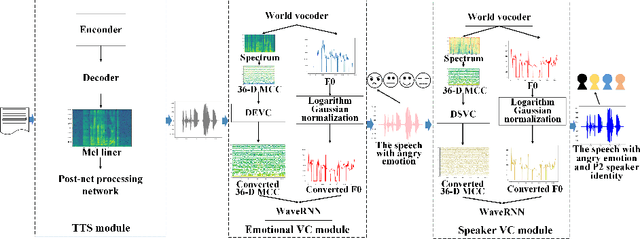
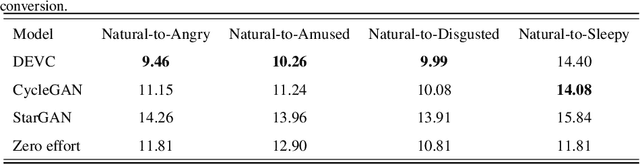
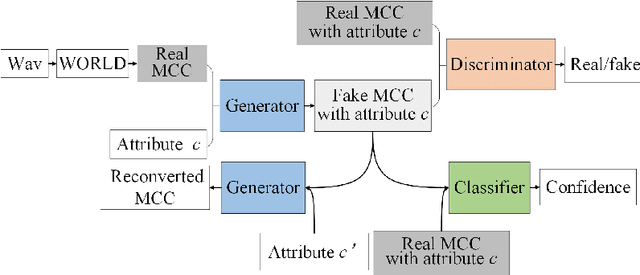
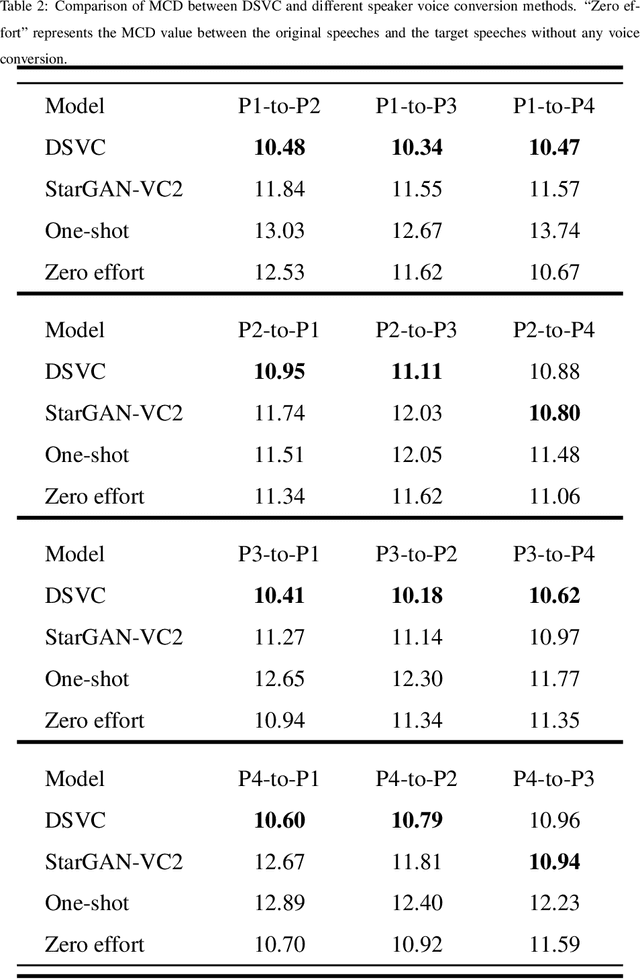
Text-to-Speech (TTS) synthesis plays an important role in human-computer interaction. Currently, most TTS technologies focus on the naturalness of speech, namely,making the speeches sound like humans. However, the key tasks of the expression of emotion and the speaker identity are ignored, which limits the application scenarios of TTS synthesis technology. To make the synthesized speech more realistic and expand the application scenarios, we propose a multi-task anthropomorphic speech synthesis framework (MASS), which can synthesize speeches from text with specified emotion and speaker identity. The MASS framework consists of a base TTS module and two novel voice conversion modules: the emotional voice conversion module and the speaker voice conversion module. We propose deep emotion voice conversion model (DEVC) and deep speaker voice conversion model (DSVC) based on convolution residual networks. It solves the problem of feature loss during voice conversion. The model trainings are independent of parallel datasets, and are capable of many-to-many voice conversion. In the emotional voice conversion, speaker voice conversion experiments, as well as the multi-task speech synthesis experiments, experimental results show DEVC and DSVC convert speech effectively. The quantitative and qualitative evaluation results of multi-task speech synthesis experiments show MASS can effectively synthesis speech with specified text, emotion and speaker identity.