 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMask2Hand: Learning to Predict the 3D Hand Pose and Shape from Shadow
Paper and Code
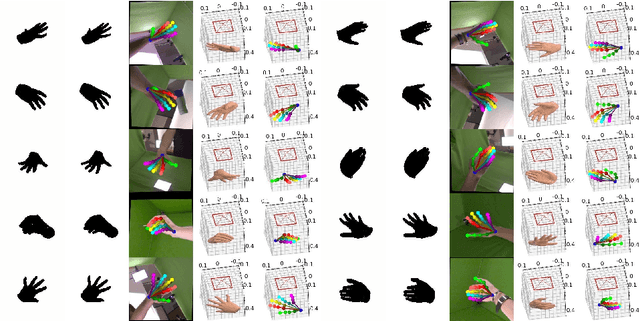

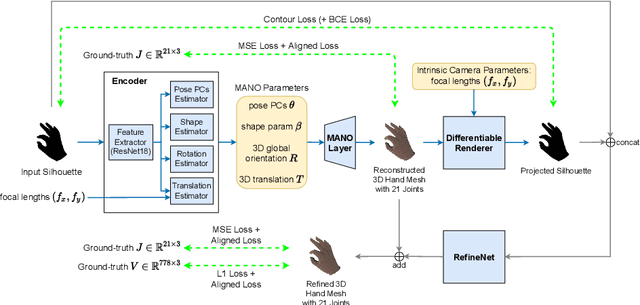

We present a self-trainable method, Mask2Hand, which learns to solve the challenging task of predicting 3D hand pose and shape from a 2D binary mask of hand silhouette/shadow without additional manually-annotated data. Given the intrinsic camera parameters and the parametric hand model in the camera space, we adopt the differentiable rendering technique to project 3D estimations onto the 2D binary silhouette space. By applying a tailored combination of losses between the rendered silhouette and the input binary mask, we are able to integrate the self-guidance mechanism into our end-to-end optimization process for constraining global mesh registration and hand pose estimation. The experiments show that our method, which takes a single binary mask as the input, can achieve comparable prediction accuracy on both unaligned and aligned settings as state-of-the-art methods that require RGB or depth inputs.