 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM-Vec: Matryoshka Speaker Embeddings with Flexible Dimensions
Paper and Code



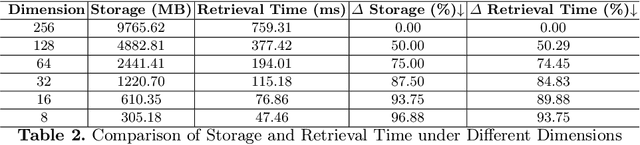
Fixed-dimensional speaker embeddings have become the dominant approach in speaker modeling, typically spanning hundreds to thousands of dimensions. These dimensions are hyperparameters that are not specifically picked, nor are they hierarchically ordered in terms of importance. In large-scale speaker representation databases, reducing the dimensionality of embeddings can significantly lower storage and computational costs. However, directly training low-dimensional representations often yields suboptimal performance. In this paper, we introduce the Matryoshka speaker embedding, a method that allows dynamic extraction of sub-dimensions from the embedding while maintaining performance. Our approach is validated on the VoxCeleb dataset, demonstrating that it can achieve extremely low-dimensional embeddings, such as 8 dimensions, while preserving high speaker verification performance.