 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLowResourceEval-2019: a shared task on morphological analysis for low-resource languages
Paper and Code
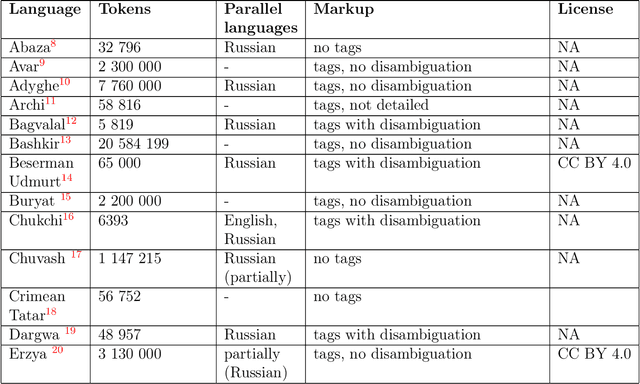

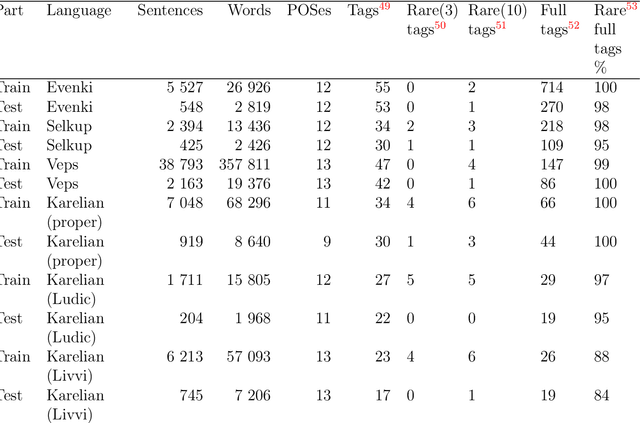
The paper describes the results of the first shared task on morphological analysis for the languages of Russia, namely, Evenki, Karelian, Selkup, and Veps. For the languages in question, only small-sized corpora are available. The tasks include morphological analysis, word form generation and morpheme segmentation. Four teams participated in the shared task. Most of them use machine-learning approaches, outperforming the existing rule-based ones. The article describes the datasets prepared for the shared tasks and contains analysis of the participants' solutions. Language corpora having different formats were transformed into CONLL-U format. The universal format makes the datasets comparable to other language corpura and facilitates using them in other NLP tasks.