 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Complexity LSTM Training and Inference with FloatSD8 Weight Representation
Paper and Code
Jan 23, 2020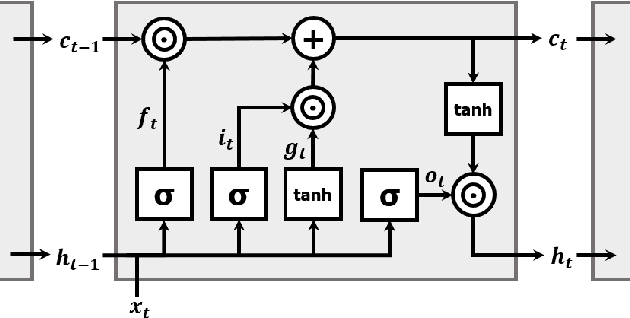

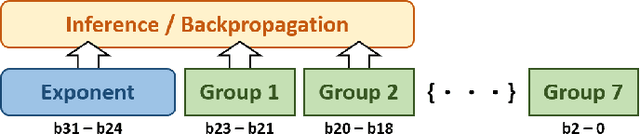
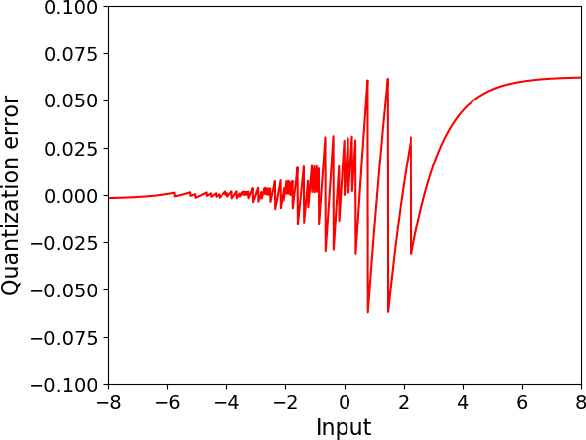
The FloatSD technology has been shown to have excellent performance on low-complexity convolutional neural networks (CNNs) training and inference. In this paper, we applied FloatSD to recurrent neural networks (RNNs), specifically long short-term memory (LSTM). In addition to FloatSD weight representation, we quantized the gradients and activations in model training to 8 bits. Moreover, the arithmetic precision for accumulations and the master copy of weights were reduced from 32 bits to 16 bits. We demonstrated that the proposed training scheme can successfully train several LSTM models from scratch, while fully preserving model accuracy. Finally, to verify the proposed method's advantage in implementation, we designed an LSTM neuron circuit and showed that it achieved significantly reduced die area and power consumption.