 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLog-Linear RNNs: Towards Recurrent Neural Networks with Flexible Prior Knowledge
Paper and Code
Dec 16, 2016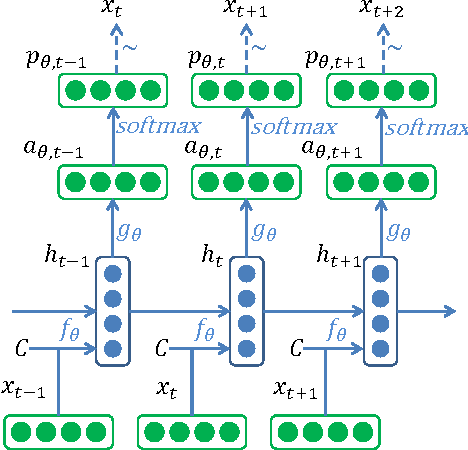

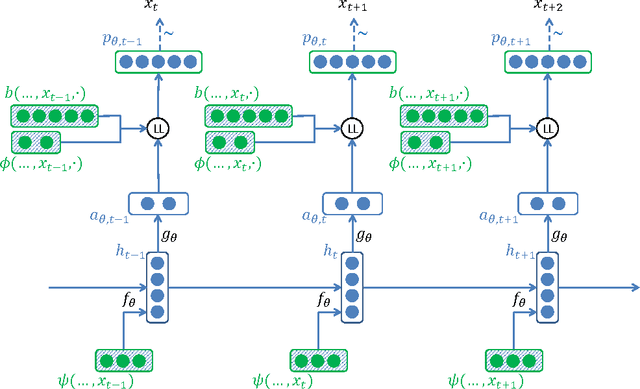

We introduce LL-RNNs (Log-Linear RNNs), an extension of Recurrent Neural Networks that replaces the softmax output layer by a log-linear output layer, of which the softmax is a special case. This conceptually simple move has two main advantages. First, it allows the learner to combat training data sparsity by allowing it to model words (or more generally, output symbols) as complex combinations of attributes without requiring that each combination is directly observed in the training data (as the softmax does). Second, it permits the inclusion of flexible prior knowledge in the form of a priori specified modular features, where the neural network component learns to dynamically control the weights of a log-linear distribution exploiting these features. We conduct experiments in the domain of language modelling of French, that exploit morphological prior knowledge and show an important decrease in perplexity relative to a baseline RNN. We provide other motivating iillustrations, and finally argue that the log-linear and the neural-network components contribute complementary strengths to the LL-RNN: the LL aspect allows the model to incorporate rich prior knowledge, while the NN aspect, according to the "representation learning" paradigm, allows the model to discover novel combination of characteristics.