 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMTemporalComparator: A Tool for Analysing Differences in Temporal Adaptations of Large Language Models
Paper and Code


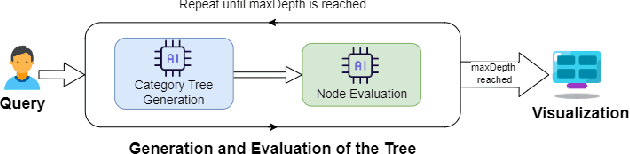
This study addresses the challenges of analyzing temporal discrepancies in large language models (LLMs) trained on data from different time periods. To facilitate the automatic exploration of these differences, we propose a novel system that compares in a systematic way the outputs of two LLM versions based on user-defined queries. The system first generates a hierarchical topic structure rooted in a user-specified keyword, allowing for an organized comparison of topical categories. Subsequently, it evaluates the generated text by both LLMs to identify differences in vocabulary, information presentation, and underlying themes. This fully automated approach not only streamlines the identification of shifts in public opinion and cultural norms but also enhances our understanding of the adaptability and robustness of machine learning applications in response to temporal changes. By fostering research in continual model adaptation and comparative summarization, this work contributes to the development of more transparent machine learning models capable of capturing the nuances of evolving societal contexts.