 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs with Personalities in Multi-issue Negotiation Games
Paper and Code
May 08, 2024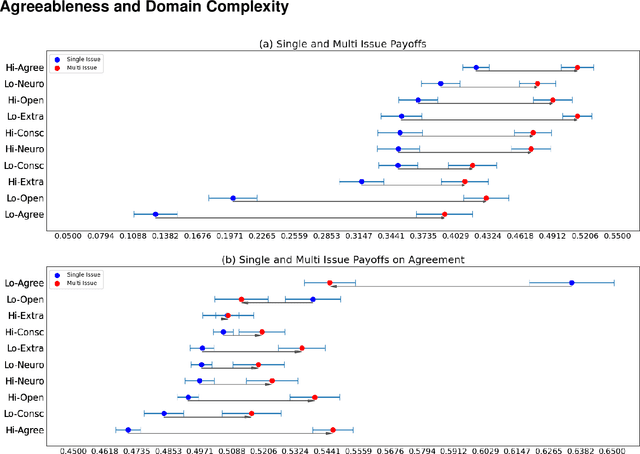
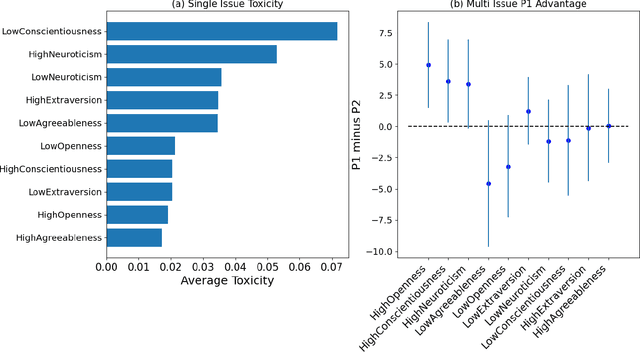
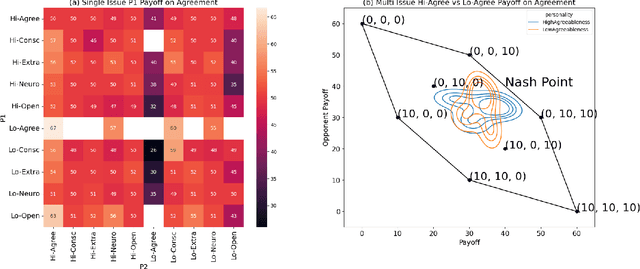
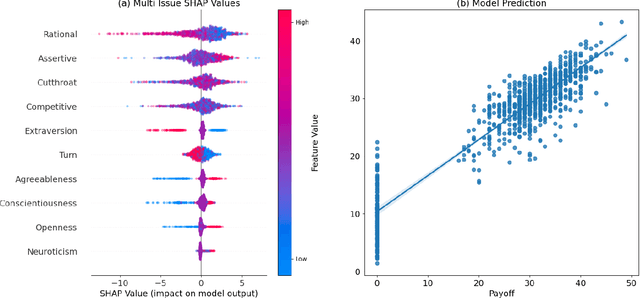
Powered by large language models (LLMs), AI agents have become capable of many human tasks. Using the most canonical definitions of the Big Five personality, we measure the ability of LLMs to negotiate within a game-theoretical framework, as well as methodological challenges to measuring notions of fairness and risk. Simulations (n=1,500) for both single-issue and multi-issue negotiation reveal increase in domain complexity with asymmetric issue valuations improve agreement rates but decrease surplus from aggressive negotiation. Through gradient-boosted regression and Shapley explainers, we find high openness, conscientiousness, and neuroticism are associated with fair tendencies; low agreeableness and low openness are associated with rational tendencies. Low conscientiousness is associated with high toxicity. These results indicate that LLMs may have built-in guardrails that default to fair behavior, but can be "jail broken" to exploit agreeable opponents. We also offer pragmatic insight in how negotiation bots can be designed, and a framework of assessing negotiation behavior based on game theory and computational social science.