 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeListen and Move: Improving GANs Coherency in Agnostic Sound-to-Video Generation
Paper and Code
Jun 23, 2024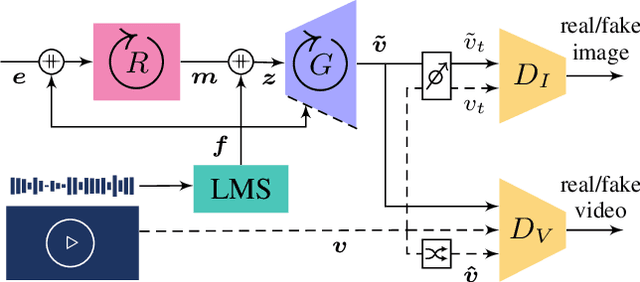

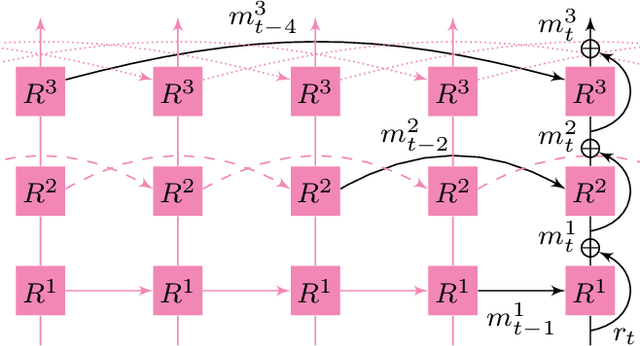
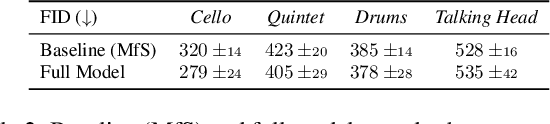
Deep generative models have demonstrated the ability to create realistic audiovisual content, sometimes driven by domains of different nature. However, smooth temporal dynamics in video generation is a challenging problem. This work focuses on generic sound-to-video generation and proposes three main features to enhance both image quality and temporal coherency in generative adversarial models: a triple sound routing scheme, a multi-scale residual and dilated recurrent network for extended sound analysis, and a novel recurrent and directional convolutional layer for video prediction. Each of the proposed features improves, in both quality and coherency, the baseline neural architecture typically used in the SoTA, with the video prediction layer providing an extra temporal refinement.