 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiFT: A Scalable Framework for Measuring Fairness in ML Applications
Paper and Code
Aug 14, 2020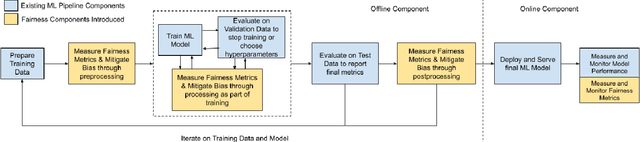
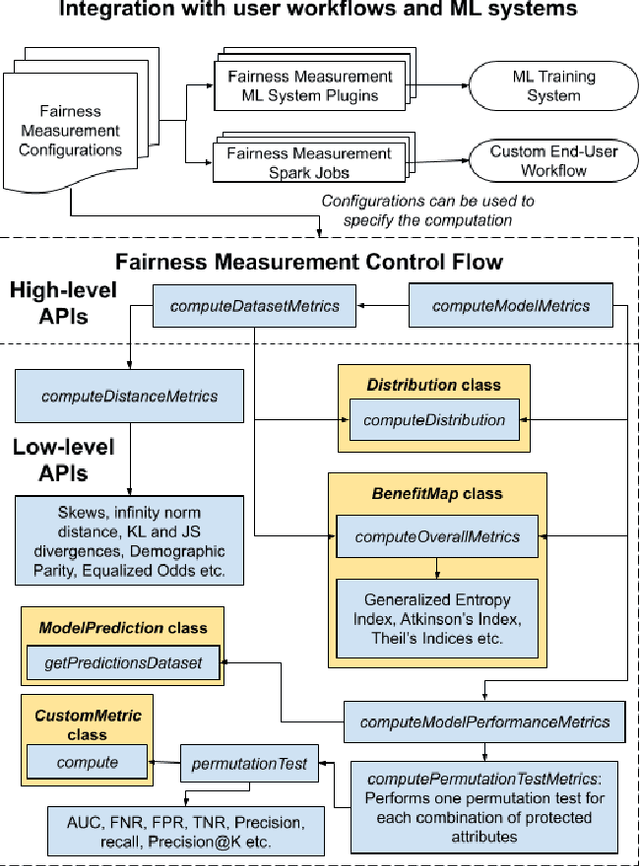

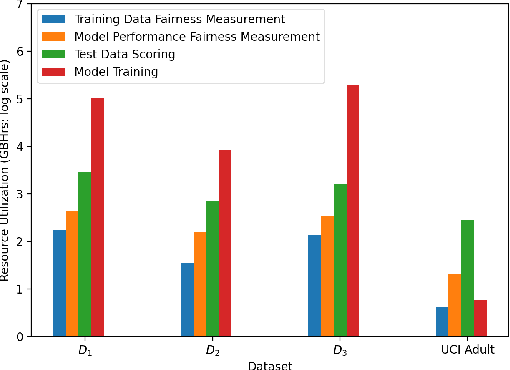
Many internet applications are powered by machine learned models, which are usually trained on labeled datasets obtained through either implicit / explicit user feedback signals or human judgments. Since societal biases may be present in the generation of such datasets, it is possible for the trained models to be biased, thereby resulting in potential discrimination and harms for disadvantaged groups. Motivated by the need for understanding and addressing algorithmic bias in web-scale ML systems and the limitations of existing fairness toolkits, we present the LinkedIn Fairness Toolkit (LiFT), a framework for scalable computation of fairness metrics as part of large ML systems. We highlight the key requirements in deployed settings, and present the design of our fairness measurement system. We discuss the challenges encountered in incorporating fairness tools in practice and the lessons learned during deployment at LinkedIn. Finally, we provide open problems based on practical experience.