 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge(Machine) Learning to Improve the Empirical Performance of Discrete Algorithms
Paper and Code
Sep 29, 2021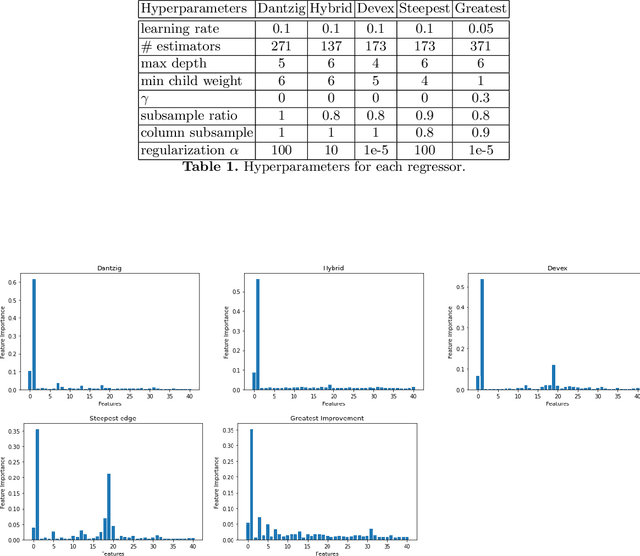
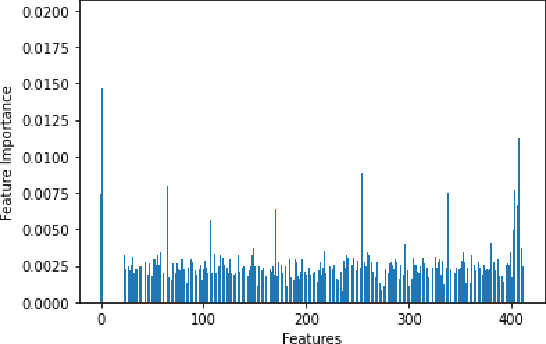
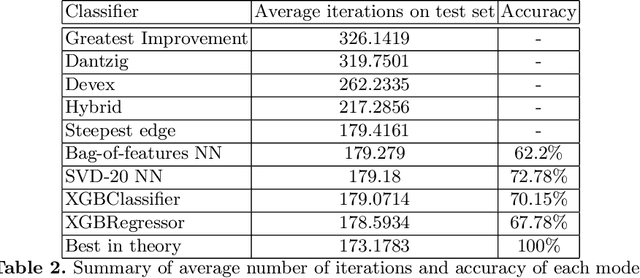
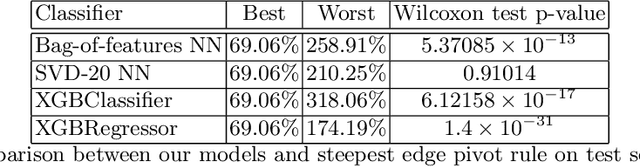
This paper discusses a data-driven, empirically-based framework to make algorithmic decisions or recommendations without expert knowledge. We improve the performance of two algorithmic case studies: the selection of a pivot rule for the Simplex method and the selection of an all-pair shortest paths algorithm. We train machine learning methods to select the optimal algorithm for given data without human expert opinion. We use two types of techniques, neural networks and boosted decision trees. We concluded, based on our experiments, that: 1) Our selection framework recommends various pivot rules that improve overall total performance over just using a fixed default pivot rule. Over many years experts identified steepest-edge pivot rule as a favorite pivot rule. Our data analysis corroborates that the number of iterations by steepest-edge is no more than 4 percent more than the optimal selection which corroborates human expert knowledge, but this time the knowledge was obtained using machine learning. Here our recommendation system is best when using gradient boosted trees. 2) For the all-pairs shortest path problem, the models trained made a large improvement and our selection is on average .07 percent away from the optimal choice. The conclusions do not seem to be affected by the machine learning method we used. We tried to make a parallel analysis of both algorithmic problems, but it is clear that there are intrinsic differences. For example, in the all-pairs shortest path problem the graph density is a reasonable predictor, but there is no analogous single parameter for decisions in the Simplex method.