 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Representations of Social Media Users
Paper and Code
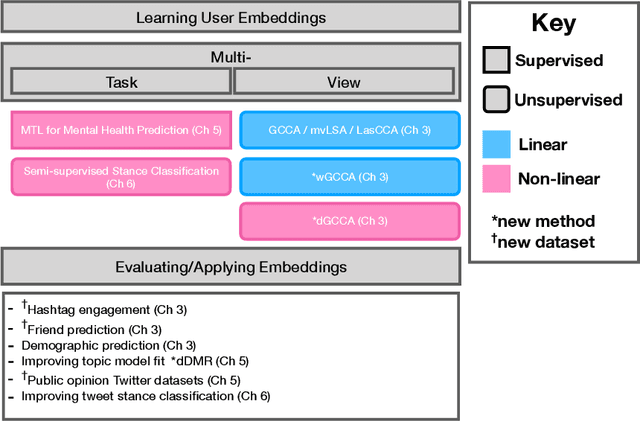
User representations are routinely used in recommendation systems by platform developers, targeted advertisements by marketers, and by public policy researchers to gauge public opinion across demographic groups. Computer scientists consider the problem of inferring user representations more abstractly; how does one extract a stable user representation - effective for many downstream tasks - from a medium as noisy and complicated as social media? The quality of a user representation is ultimately task-dependent (e.g. does it improve classifier performance, make more accurate recommendations in a recommendation system) but there are proxies that are less sensitive to the specific task. Is the representation predictive of latent properties such as a person's demographic features, socioeconomic class, or mental health state? Is it predictive of the user's future behavior? In this thesis, we begin by showing how user representations can be learned from multiple types of user behavior on social media. We apply several extensions of generalized canonical correlation analysis to learn these representations and evaluate them at three tasks: predicting future hashtag mentions, friending behavior, and demographic features. We then show how user features can be employed as distant supervision to improve topic model fit. Finally, we show how user features can be integrated into and improve existing classifiers in the multitask learning framework. We treat user representations - ground truth gender and mental health features - as auxiliary tasks to improve mental health state prediction. We also use distributed user representations learned in the first chapter to improve tweet-level stance classifiers, showing that distant user information can inform classification tasks at the granularity of a single message.