 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Hard Retrieval Cross Attention for Transformer
Paper and Code
Sep 30, 2020
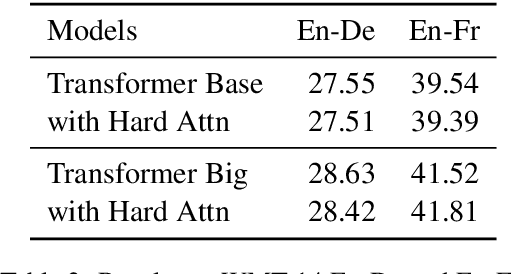
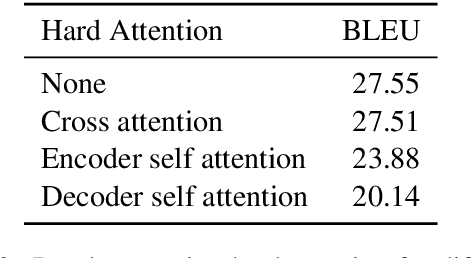
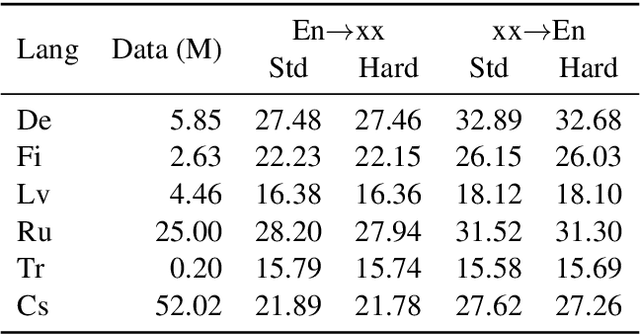
The Transformer translation model that based on the multi-head attention mechanism can be parallelized easily and lead to competitive performance in machine translation. The multi-head attention network performs the scaled dot-product attention function in parallel, empowering the model by jointly attending to information from different representation subspaces at different positions. Though its advantages in parallelization, many previous works suggest the computation of the attention mechanism is not sufficiently efficient, especially when processing long sequences, and propose approaches to improve its efficiency with long sentences. In this paper, we accelerate the inference of the scaled dot-product attention in another perspective. Specifically, instead of squeezing the sequence to attend, we simplify the computation of the scaled dot-product attention by learning a hard retrieval attention which only attends to one token in the sentence rather than all tokens. Since the hard attention mechanism only attends to one position, the matrix multiplication between attention probabilities and the value sequence in the standard scaled dot-product attention can be replaced by a simple and efficient retrieval operation. As a result, our hard retrieval attention mechanism can empirically accelerate the scaled dot-product attention for both long and short sequences by 66.5%, while performing competitively in a wide range of machine translation tasks when using for cross attention networks.