 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Abstract Visual Reasoning via Task Decomposition: A Case Study in Raven Progressive Matrices
Paper and Code

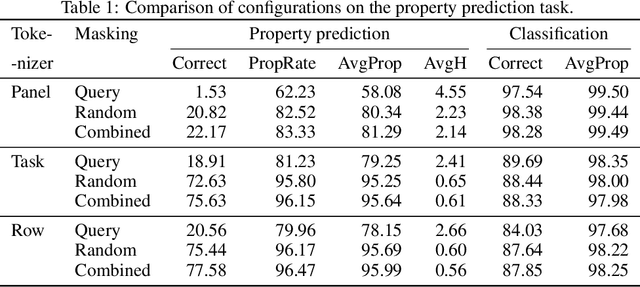
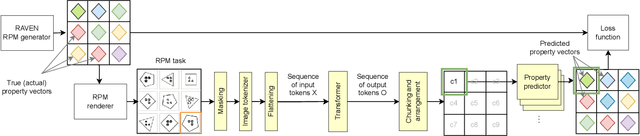
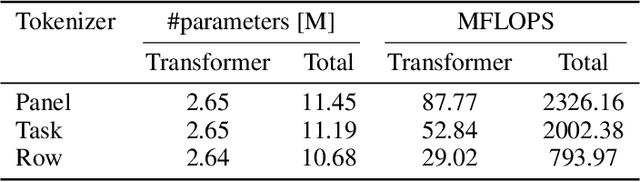
One of the challenges in learning to perform abstract reasoning is that problems are often posed as monolithic tasks, with no intermediate subgoals. In Raven Progressive Matrices (RPM), the task is to choose one of the available answers given a context, where both contexts and answers are composite images featuring multiple objects in various spatial arrangements. As this high-level goal is the only guidance available, learning is challenging and most contemporary solvers tend to be opaque. In this study, we propose a deep learning architecture based on the transformer blueprint which, rather than directly making the above choice, predicts the visual properties of individual objects and their arrangements. The multidimensional predictions obtained in this way are then directly juxtaposed to choose the answer. We consider a few ways in which the model parses the visual input into tokens and several regimes of masking parts of the input in self-supervised training. In experimental assessment, the models not only outperform state-of-the-art methods but also provide interesting insights and partial explanations about the inference. The design of the method also makes it immune to biases that are known to exist in some RPM benchmarks.