 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a Deep ConvNet for Multi-label Classification with Partial Labels
Paper and Code
Feb 26, 2019


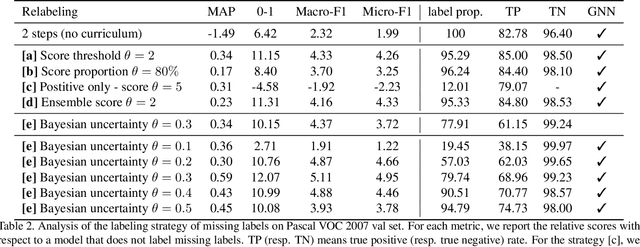
Deep ConvNets have shown great performance for single-label image classification (e.g. ImageNet), but it is necessary to move beyond the single-label classification task because pictures of everyday life are inherently multi-label. Multi-label classification is a more difficult task than single-label classification because both the input images and output label spaces are more complex. Furthermore, collecting clean multi-label annotations is more difficult to scale-up than single-label annotations. To reduce the annotation cost, we propose to train a model with partial labels i.e. only some labels are known per image. We first empirically compare different labeling strategies to show the potential for using partial labels on multi-label datasets. Then to learn with partial labels, we introduce a new classification loss that exploits the proportion of known labels per example. Our approach allows the use of the same training settings as when learning with all the annotations. We further explore several curriculum learning based strategies to predict missing labels. Experiments are performed on three large-scale multi-label datasets: MS COCO, NUS-WIDE and Open Images.