 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayered gradient accumulation and modular pipeline parallelism: fast and efficient training of large language models
Paper and Code
Jun 04, 2021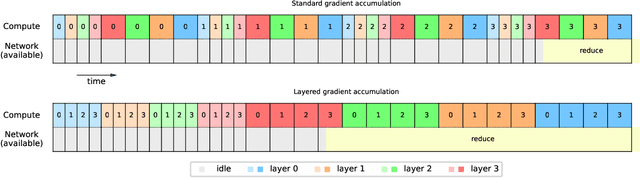
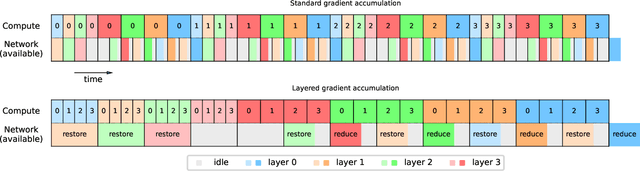
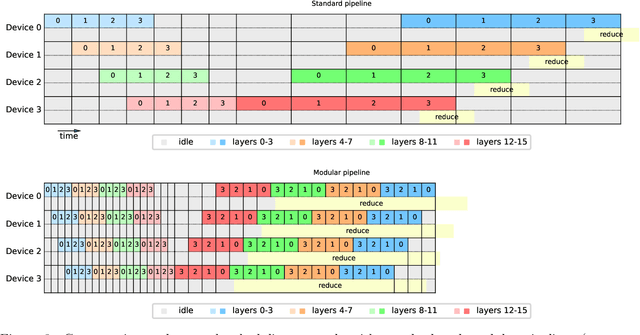
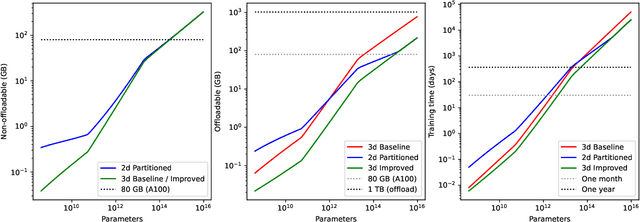
The advent of the transformer has sparked a quick growth in the size of language models, far outpacing hardware improvements. (Dense) transformers are expected to reach the trillion-parameter scale in the near future, for which training requires thousands or even tens of thousands of GPUs. We investigate the challenges of training at this scale and beyond on commercially available hardware. In particular, we analyse the shortest possible training time for different configurations of distributed training, leveraging empirical scaling laws for language models to estimate the optimal (critical) batch size. Contrary to popular belief, we find no evidence for a memory wall, and instead argue that the real limitation -- other than the cost -- lies in the training duration. In addition to this analysis, we introduce two new methods, \textit{layered gradient accumulation} and \textit{modular pipeline parallelism}, which together cut the shortest training time by half. The methods also reduce data movement, lowering the network requirement to a point where a fast InfiniBand connection is not necessary. This increased network efficiency also improve on the methods introduced with the ZeRO optimizer, reducing the memory usage to a tiny fraction of the available GPU memory.