 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Variable Algorithms for Multimodal Learning and Sensor Fusion
Paper and Code
Apr 23, 2019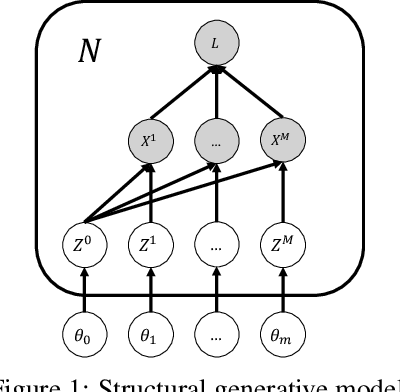

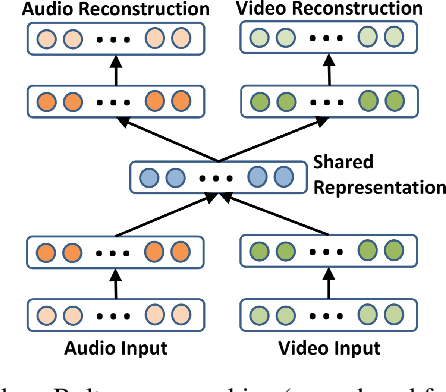
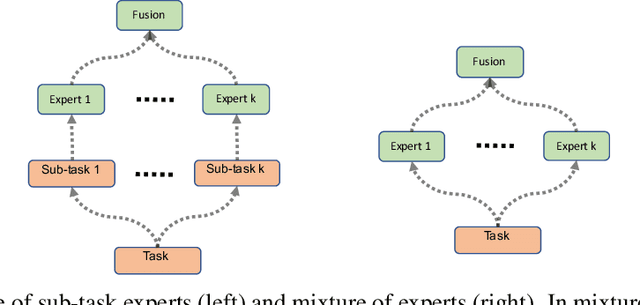
Multimodal learning has been lacking principled ways of combining information from different modalities and learning a low-dimensional manifold of meaningful representations. We study multimodal learning and sensor fusion from a latent variable perspective. We first present a regularized recurrent attention filter for sensor fusion. This algorithm can dynamically combine information from different types of sensors in a sequential decision making task. Each sensor is bonded with a modular neural network to maximize utility of its own information. A gating modular neural network dynamically generates a set of mixing weights for outputs from sensor networks by balancing utility of all sensors' information. We design a co-learning mechanism to encourage co-adaption and independent learning of each sensor at the same time, and propose a regularization based co-learning method. In the second part, we focus on recovering the manifold of latent representation. We propose a co-learning approach using probabilistic graphical model which imposes a structural prior on the generative model: multimodal variational RNN (MVRNN) model, and derive a variational lower bound for its objective functions. In the third part, we extend the siamese structure to sensor fusion for robust acoustic event detection. We perform experiments to investigate the latent representations that are extracted; works will be done in the following months. Our experiments show that the recurrent attention filter can dynamically combine different sensor inputs according to the information carried in the inputs. We consider MVRNN can identify latent representations that are useful for many downstream tasks such as speech synthesis, activity recognition, and control and planning. Both algorithms are general frameworks which can be applied to other tasks where different types of sensors are jointly used for decision making.