 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLate fusion ensembles for speech recognition on diverse input audio representations
Paper and Code
Dec 01, 2024

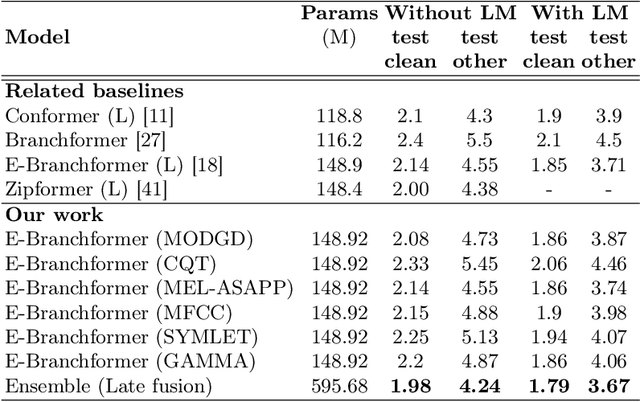

We explore diverse representations of speech audio, and their effect on a performance of late fusion ensemble of E-Branchformer models, applied to Automatic Speech Recognition (ASR) task. Although it is generally known that ensemble methods often improve the performance of the system even for speech recognition, it is very interesting to explore how ensembles of complex state-of-the-art models, such as medium-sized and large E-Branchformers, cope in this setting when their base models are trained on diverse representations of the input speech audio. The results are evaluated on four widely-used benchmark datasets: \textit{Librispeech, Aishell, Gigaspeech}, \textit{TEDLIUMv2} and show that improvements of $1\% - 14\%$ can still be achieved over the state-of-the-art models trained using comparable techniques on these datasets. A noteworthy observation is that such ensemble offers improvements even with the use of language models, although the gap is closing.