 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models in Sport Science & Medicine: Opportunities, Risks and Considerations
Paper and Code
May 05, 2023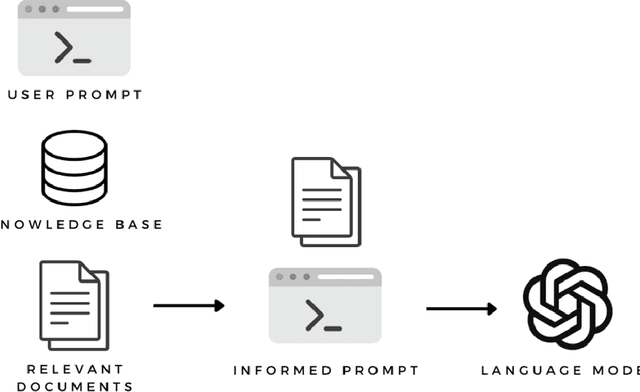
This paper explores the potential opportunities, risks, and challenges associated with the use of large language models (LLMs) in sports science and medicine. LLMs are large neural networks with transformer style architectures trained on vast amounts of textual data, and typically refined with human feedback. LLMs can perform a large range of natural language processing tasks. In sports science and medicine, LLMs have the potential to support and augment the knowledge of sports medicine practitioners, make recommendations for personalised training programs, and potentially distribute high-quality information to practitioners in developing countries. However, there are also potential risks associated with the use and development of LLMs, including biases in the dataset used to create the model, the risk of exposing confidential data, the risk of generating harmful output, and the need to align these models with human preferences through feedback. Further research is needed to fully understand the potential applications of LLMs in sports science and medicine and to ensure that their use is ethical and beneficial to athletes, clients, patients, practitioners, and the general public.