 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Can Be Used to Estimate the Ideologies of Politicians in a Zero-Shot Learning Setting
Paper and Code
Mar 22, 2023

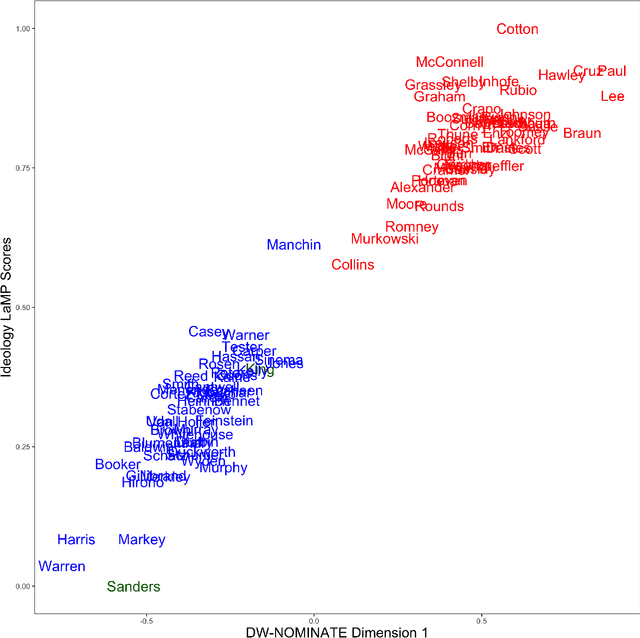
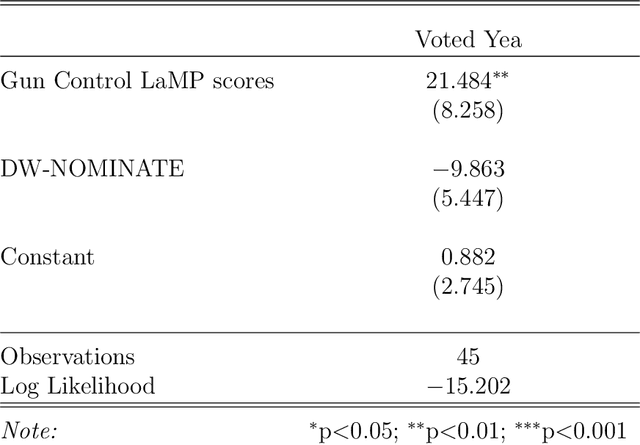
The mass aggregation of knowledge embedded in large language models (LLMs) holds the promise of new solutions to problems of observability and measurement in the social sciences. We examine the utility of one such model for a particularly difficult measurement task: measuring the latent ideology of lawmakers, which allows us to better understand functions that are core to democracy, such as how politics shape policy and how political actors represent their constituents. We scale the senators of the 116th United States Congress along the liberal-conservative spectrum by prompting ChatGPT to select the more liberal (or conservative) senator in pairwise comparisons. We show that the LLM produced stable answers across repeated iterations, did not hallucinate, and was not simply regurgitating information from a single source. This new scale strongly correlates with pre-existing liberal-conservative scales such as NOMINATE, but also differs in several important ways, such as correctly placing senators who vote against their party for far-left or far-right ideological reasons on the extreme ends. The scale also highly correlates with ideological measures based on campaign giving and political activists' perceptions of these senators. In addition to the potential for better-automated data collection and information retrieval, our results suggest LLMs are likely to open new avenues for measuring latent constructs like ideology that rely on aggregating large quantities of data from public sources.