 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models Show Stable Value Orientations Across Diverse Role-Plays
Paper and Code
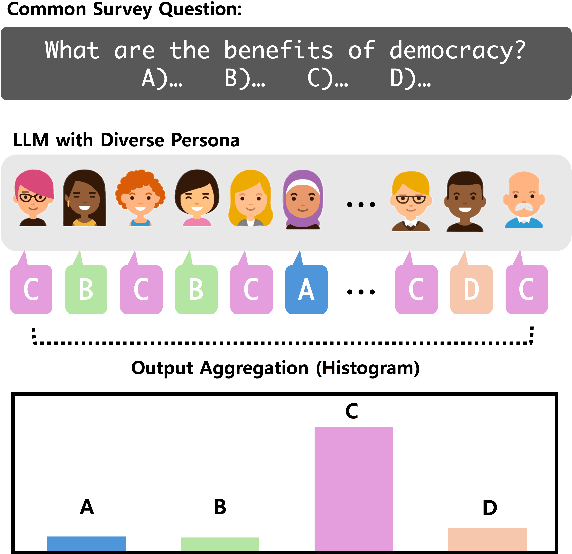



We demonstrate that large language models (LLMs) exhibit consistent value orientations despite adopting diverse personas, revealing a persistent inertia in their responses that remains stable across the variety of roles they are prompted to assume. To systematically explore this phenomenon, we introduce the role-play-at-scale methodology, which involves prompting LLMs with randomized, diverse personas and analyzing the macroscopic trend of their responses. Unlike previous works that simply feed these questions to LLMs as if testing human subjects, our role-play-at-scale methodology diagnoses inherent tendencies in a systematic and scalable manner by: (1) prompting the model to act in different random personas and (2) asking the same question multiple times for each random persona. This approach reveals consistent patterns in LLM responses across diverse role-play scenarios, indicating deeply encoded inherent tendencies. Our findings contribute to the discourse on value alignment in foundation models and demonstrate the efficacy of role-play-at-scale as a diagnostic tool for uncovering encoded biases in LLMs.