 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage bias in Visual Question Answering: A Survey and Taxonomy
Paper and Code
Nov 16, 2021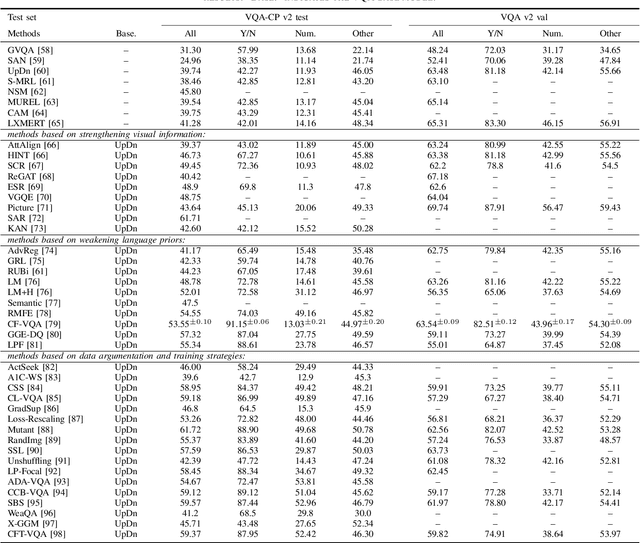
Visual question answering (VQA) is a challenging task, which has attracted more and more attention in the field of computer vision and natural language processing. However, the current visual question answering has the problem of language bias, which reduces the robustness of the model and has an adverse impact on the practical application of visual question answering. In this paper, we conduct a comprehensive review and analysis of this field for the first time, and classify the existing methods according to three categories, including enhancing visual information, weakening language priors, data enhancement and training strategies. At the same time, the relevant representative methods are introduced, summarized and analyzed in turn. The causes of language bias are revealed and classified. Secondly, this paper introduces the datasets mainly used for testing, and reports the experimental results of various existing methods. Finally, we discuss the possible future research directions in this field.