Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKSU KDD: Word Sense Induction by Clustering in Topic Space
Paper and Code
Feb 28, 2013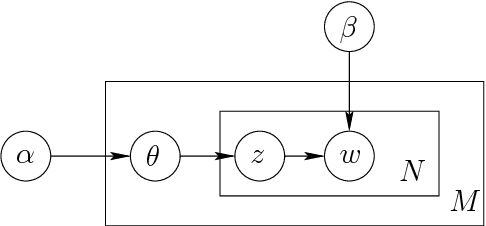

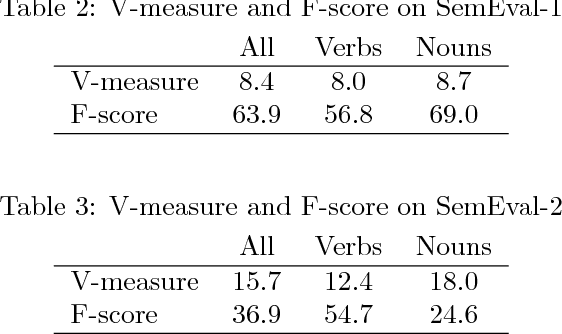
We describe our language-independent unsupervised word sense induction system. This system only uses topic features to cluster different word senses in their global context topic space. Using unlabeled data, this system trains a latent Dirichlet allocation (LDA) topic model then uses it to infer the topics distribution of the test instances. By clustering these topics distributions in their topic space we cluster them into different senses. Our hypothesis is that closeness in topic space reflects similarity between different word senses. This system participated in SemEval-2 word sense induction and disambiguation task and achieved the second highest V-measure score among all other systems.
* Proceedings of the 5th International Workshop on Semantic
Evaluation, pages 367-370, Uppsala, Sweden, July 2010. Association for
Computational Linguistics
View paper on