 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-Spreader: Learning Facial Action Unit Dynamics with Extremely Limited Labels
Paper and Code
Mar 30, 2022
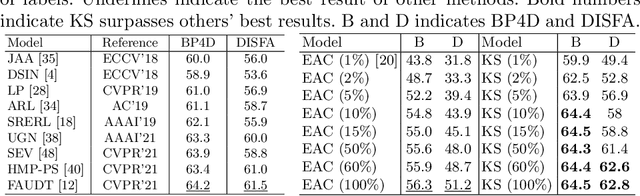
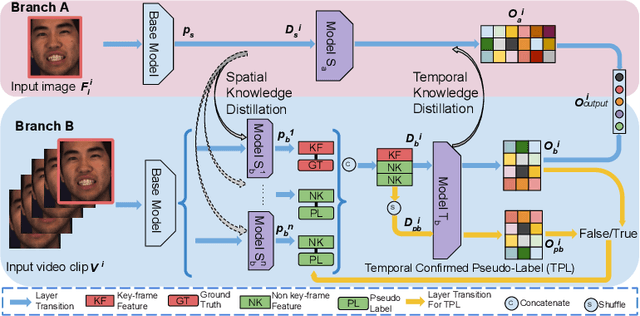

Recent studies on the automatic detection of facial action unit (AU) have extensively relied on large-sized annotations. However, manually AU labeling is difficult, time-consuming, and costly. Most existing semi-supervised works ignore the informative cues from the temporal domain, and are highly dependent on densely annotated videos, making the learning process less efficient. To alleviate these problems, we propose a deep semi-supervised framework Knowledge-Spreader (KS), which differs from conventional methods in two aspects. First, rather than only encoding human knowledge as constraints, KS also learns the Spatial-Temporal AU correlation knowledge in order to strengthen its out-of-distribution generalization ability. Second, we approach KS by applying consistency regularization and pseudo-labeling in multiple student networks alternately and dynamically. It spreads the spatial knowledge from labeled frames to unlabeled data, and completes the temporal information of partially labeled video clips. Thus, the design allows KS to learn AU dynamics from video clips with only one label allocated, which significantly reduce the requirements of using annotations. Extensive experiments demonstrate that the proposed KS achieves competitive performance as compared to the state of the arts under the circumstances of using only 2% labels on BP4D and 5% labels on DISFA. In addition, we test it on our newly developed large-scale comprehensive emotion database, which contains considerable samples across well-synchronized and aligned sensor modalities for easing the scarcity issue of annotations and identities in human affective computing. The new database will be released to the research community.