 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Guided Bidirectional Attention Network for Human-Object Interaction Detection
Paper and Code
Jul 16, 2022
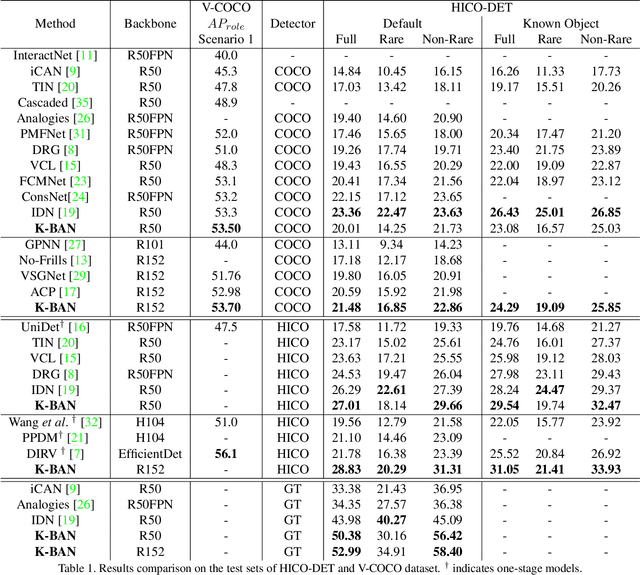
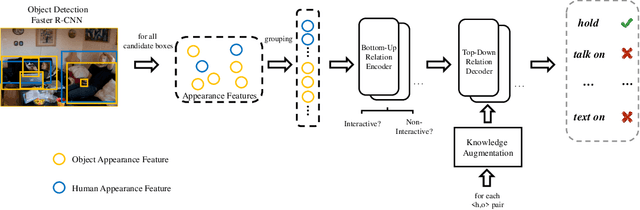
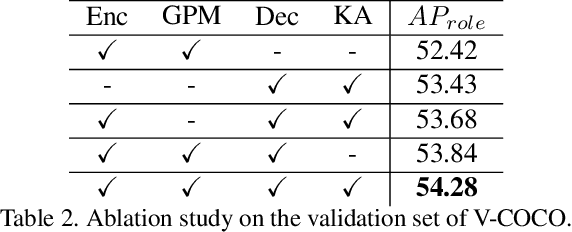
Human Object Interaction (HOI) detection is a challenging task that requires to distinguish the interaction between a human-object pair. Attention based relation parsing is a popular and effective strategy utilized in HOI. However, current methods execute relation parsing in a "bottom-up" manner. We argue that the independent use of the bottom-up parsing strategy in HOI is counter-intuitive and could lead to the diffusion of attention. Therefore, we introduce a novel knowledge-guided top-down attention into HOI, and propose to model the relation parsing as a "look and search" process: execute scene-context modeling (i.e. look), and then, given the knowledge of the target pair, search visual clues for the discrimination of the interaction between the pair. We implement the process via unifying the bottom-up and top-down attention in a single encoder-decoder based model. The experimental results show that our model achieves competitive performance on the V-COCO and HICO-DET datasets.