 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Graphs for Multilingual Language Translation and Generation
Paper and Code
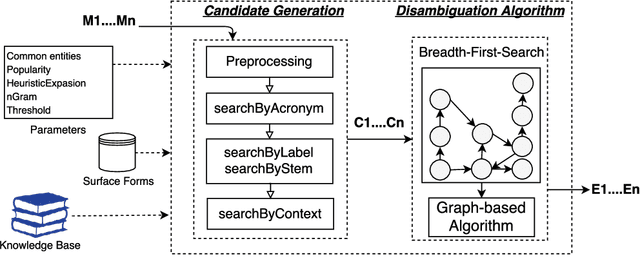
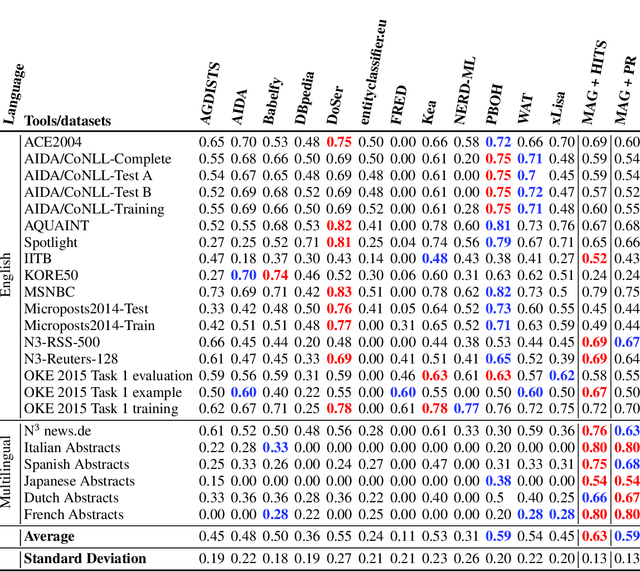
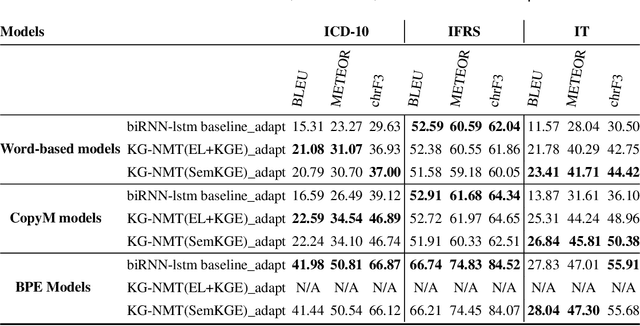
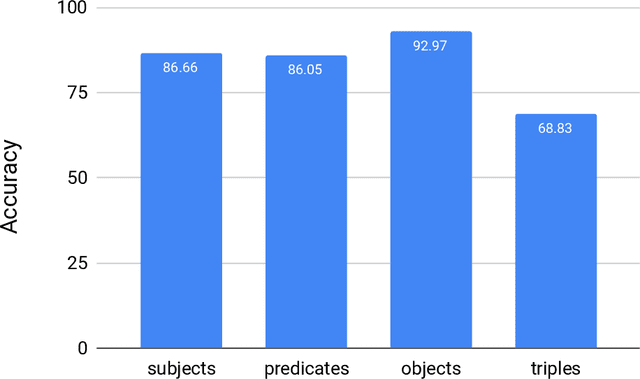
The Natural Language Processing (NLP) community has recently seen outstanding progress, catalysed by the release of different Neural Network (NN) architectures. Neural-based approaches have proven effective by significantly increasing the output quality of a large number of automated solutions for NLP tasks (Belinkov and Glass, 2019). Despite these notable advancements, dealing with entities still poses a difficult challenge as they are rarely seen in training data. Entities can be classified into two groups, i.e., proper nouns and common nouns. Proper nouns are also known as Named Entities (NE) and correspond to the name of people, organizations, or locations, e.g., John, WHO, or Canada. Common nouns describe classes of objects, e.g., spoon or cancer. Both types of entities can be found in a Knowledge Graph (KG). Recent work has successfully exploited the contribution of KGs in NLP tasks, such as Natural Language Inference (NLI) (KM et al.,2018) and Question Answering (QA) (Sorokin and Gurevych, 2018). Only a few works had exploited the benefits of KGs in Neural Machine Translation (NMT) when the work presented herein began. Additionally, few works had studied the contribution of KGs to Natural Language Generation (NLG) tasks. Moreover, the multilinguality also remained an open research area in these respective tasks (Young et al., 2018). In this thesis, we focus on the use of KGs for machine translation and the generation of texts to deal with the problems caused by entities and consequently enhance the quality of automatically generated texts.