 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKannada-MNIST: A new handwritten digits dataset for the Kannada language
Paper and Code

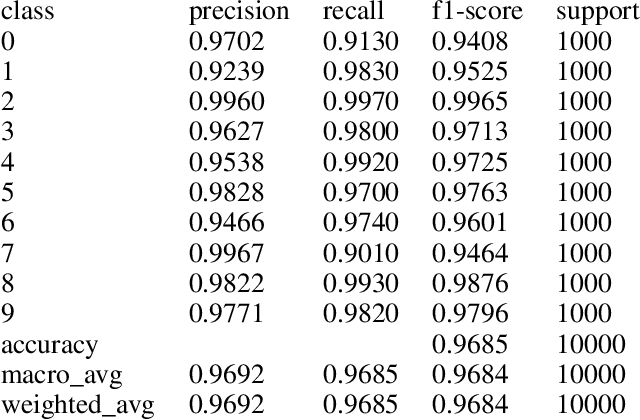

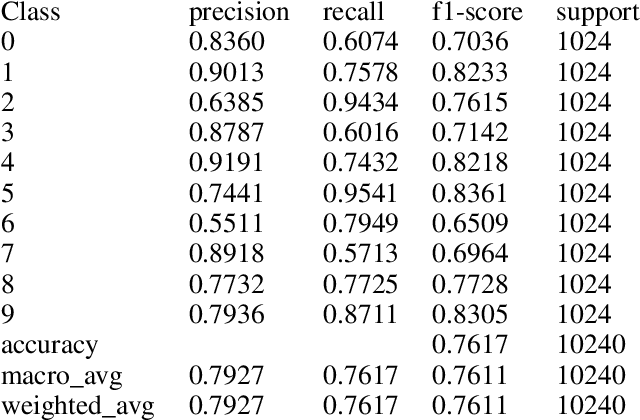
In this paper, we disseminate a new handwritten digits-dataset, termed Kannada-MNIST, for the Kannada script, that can potentially serve as a direct drop-in replacement for the original MNIST dataset. In addition to this dataset, we disseminate an additional real world handwritten dataset (with $10k$ images), which we term as the Dig-MNIST dataset that can serve as an out-of-domain test dataset. We also duly open source all the code as well as the raw scanned images along with the scanner settings so that researchers who want to try out different signal processing pipelines can perform end-to-end comparisons. We provide high level morphological comparisons with the MNIST dataset and provide baselines accuracies for the dataset disseminated. The initial baselines obtained using an oft-used CNN architecture ($96.8\%$ for the main test-set and $76.1\%$ for the Dig-MNIST test-set) indicate that these datasets do provide a sterner challenge with regards to generalizability than MNIST or the KMNIST datasets. We also hope this dissemination will spur the creation of similar datasets for all the languages that use different symbols for the numeral digits.