 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoined Audio-Visual Speech Enhancement and Recognition in the Cocktail Party: The Tug Of War Between Enhancement and Recognition Losses
Paper and Code
Apr 16, 2019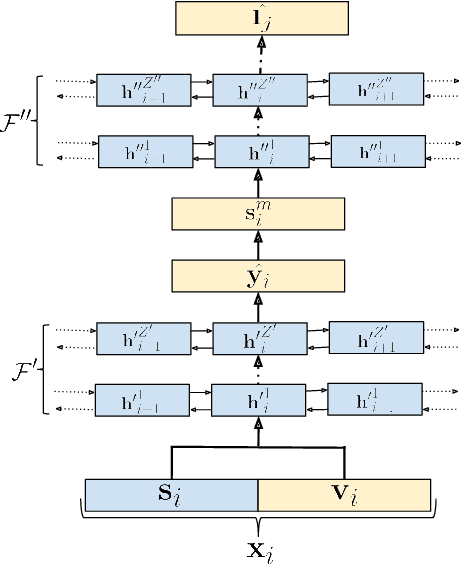
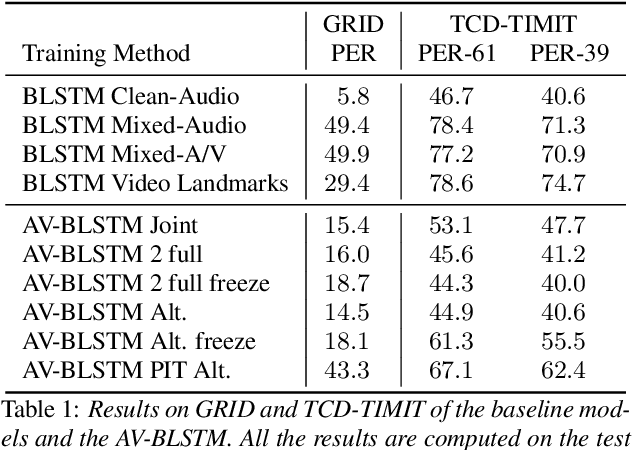
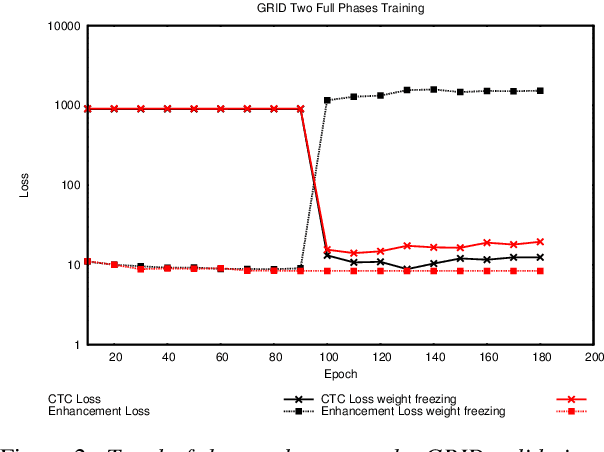
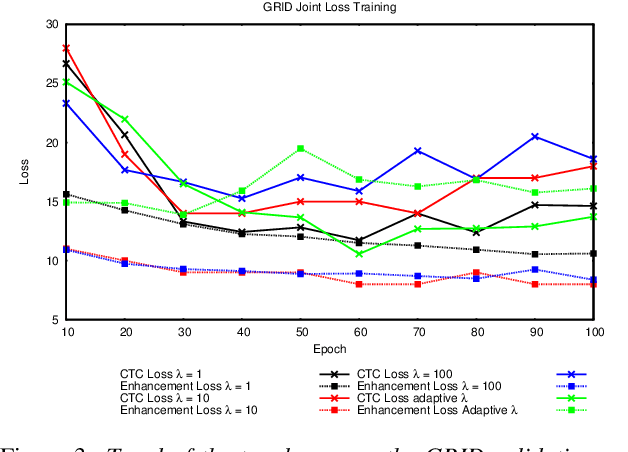
In this paper we propose an end-to-end LSTM-based model that performs single-channel speech enhancement and phone recognition in a cocktail party scenario where visual information of the target speaker is available. In the speech enhancement phase the proposed system uses a "visual attention" signal of the speaker of interest to extract her speech from the input mixed-speech signal, while in the ASR phase it recognizes her phone sequence through a phone recognizer trained with a CTC loss. It is well known that learning multiple related tasks from data simultaneously can improve performance than learning these tasks independently, therefore we decided to train the model by optimizing both tasks at the same time. This allowed us also to explore whether (and how) this joint optimization leads to better results. We analyzed different training strategies that reveal some interesting and unexpected behaviors. In particular, the experiments demonstrated that during optimization of the ASR phase the speech enhancement capability of the model significantly decreases and vice-versa. We evaluated our approach on mixed-speech versions of GRID and TCD-TIMIT. The obtained results show a remarkable drop of the Phone Error Rate (PER) compared to the audio-visual baseline models trained only to perform phone recognition phase.