 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Hard Thresholding with Adaptive Regularization: Sparser Solutions Without Sacrificing Runtime
Paper and Code
Apr 11, 2022
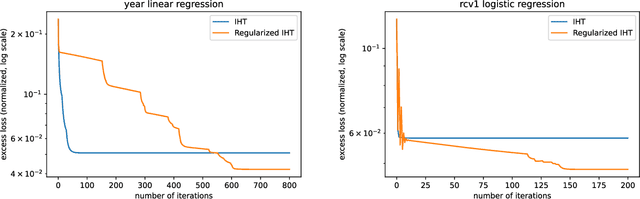
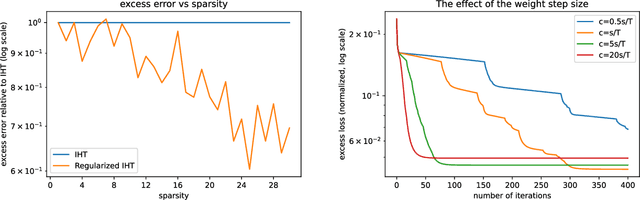
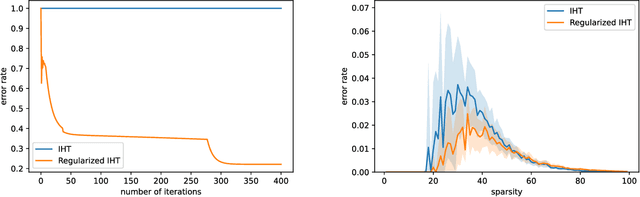
We propose a simple modification to the iterative hard thresholding (IHT) algorithm, which recovers asymptotically sparser solutions as a function of the condition number. When aiming to minimize a convex function $f(x)$ with condition number $\kappa$ subject to $x$ being an $s$-sparse vector, the standard IHT guarantee is a solution with relaxed sparsity $O(s\kappa^2)$, while our proposed algorithm, regularized IHT, returns a solution with sparsity $O(s\kappa)$. Our algorithm significantly improves over ARHT which also finds a solution of sparsity $O(s\kappa)$, as it does not require re-optimization in each iteration (and so is much faster), is deterministic, and does not require knowledge of the optimal solution value $f(x^*)$ or the optimal sparsity level $s$. Our main technical tool is an adaptive regularization framework, in which the algorithm progressively learns the weights of an $\ell_2$ regularization term that will allow convergence to sparser solutions. We also apply this framework to low rank optimization, where we achieve a similar improvement of the best known condition number dependence from $\kappa^2$ to $\kappa$.