 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs this bug severe? A text-cum-graph based model for bug severity prediction
Paper and Code


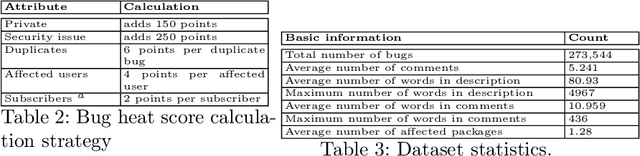
Repositories of large software systems have become commonplace. This massive expansion has resulted in the emergence of various problems in these software platforms including identification of (i) bug-prone packages, (ii) critical bugs, and (iii) severity of bugs. One of the important goals would be to mine these bugs and recommend them to the developers to resolve them. The first step to this is that one has to accurately detect the extent of severity of the bugs. In this paper, we take up this task of predicting the severity of bugs in the near future. Contextualized neural models built on the text description of a bug and the user comments about the bug help to achieve reasonably good performance. Further information on how the bugs are related to each other in terms of the ways they affect packages can be summarised in the form of a graph and used along with the text to get additional benefits.