 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIR-BERT: Leveraging BERT for Semantic Search in Background Linking for News Articles
Paper and Code
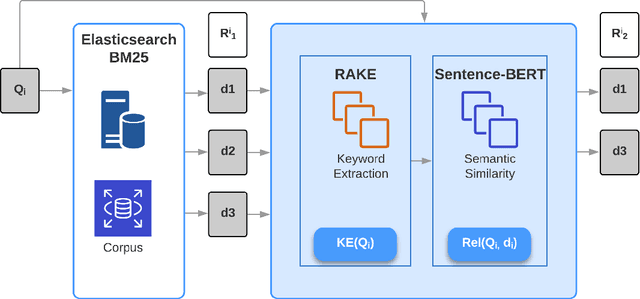
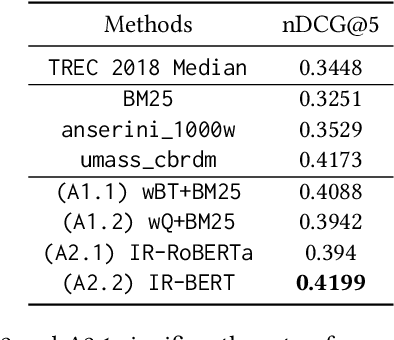
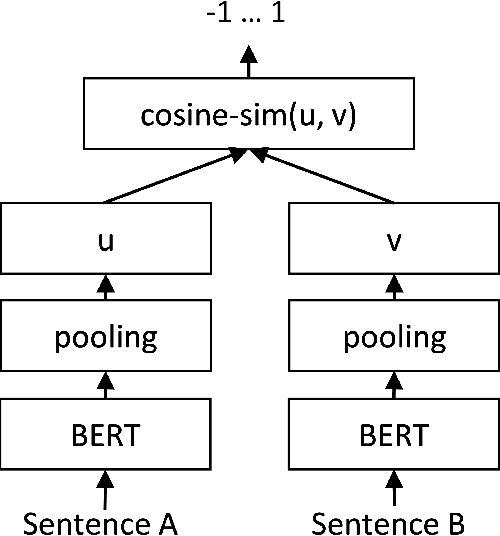
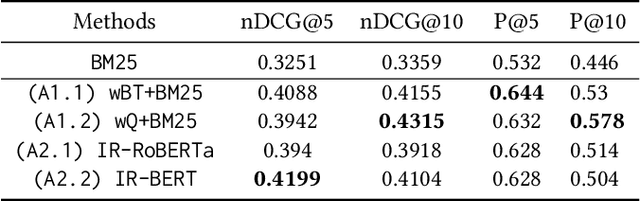
This work describes our two approaches for the background linking task of TREC 2020 News Track. The main objective of this task is to recommend a list of relevant articles that the reader should refer to in order to understand the context and gain background information of the query article. Our first approach focuses on building an effective search query by combining weighted keywords extracted from the query document and uses BM25 for retrieval. The second approach leverages the capability of SBERT (Nils Reimers et al.) to learn contextual representations of the query in order to perform semantic search over the corpus. We empirically show that employing a language model benefits our approach in understanding the context as well as the background of the query article. The proposed approaches are evaluated on the TREC 2018 Washington Post dataset and our best model outperforms the TREC median as well as the highest scoring model of 2018 in terms of the nDCG@5 metric. We further propose a diversity measure to evaluate the effectiveness of the various approaches in retrieving a diverse set of documents. This would potentially motivate researchers to work on introducing diversity in their recommended list. We have open sourced our implementation on Github and plan to submit our runs for the background linking task in TREC 2020.