 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigation of Using VAE for i-Vector Speaker Verification
Paper and Code
May 25, 2017


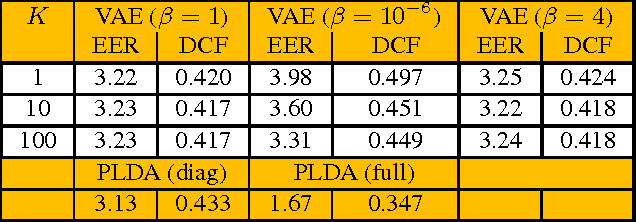
New system for i-vector speaker recognition based on variational autoencoder (VAE) is investigated. VAE is a promising approach for developing accurate deep nonlinear generative models of complex data. Experiments show that VAE provides speaker embedding and can be effectively trained in an unsupervised manner. LLR estimate for VAE is developed. Experiments on NIST SRE 2010 data demonstrate its correctness. Additionally, we show that the performance of VAE-based system in the i-vectors space is close to that of the diagonal PLDA. Several interesting results are also observed in the experiments with $\beta$-VAE. In particular, we found that for $\beta\ll 1$, VAE can be trained to capture the features of complex input data distributions in an effective way, which is hard to obtain in the standard VAE ($\beta=1$).