 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntroduction to the 1st Place Winning Model of OpenImages Relationship Detection Challenge
Paper and Code
Nov 01, 2018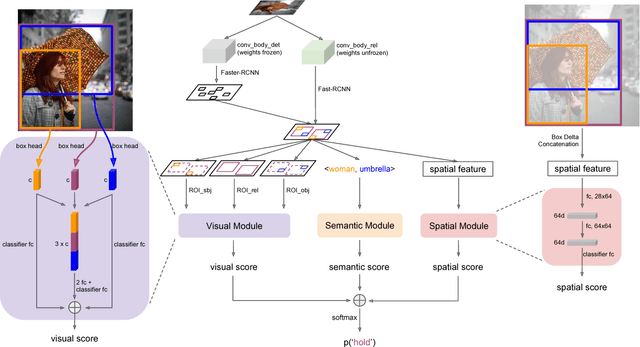

This article describes the model we built that achieved 1st place in the OpenImage Visual Relationship Detection Challenge on Kaggle. Three key factors contribute the most to our success: 1) language bias is a powerful baseline for this task. We build the empirical distribution $P(predicate|subject,object)$ in the training set and directly use that in testing. This baseline achieved the 2nd place when submitted; 2) spatial features are as important as visual features, especially for spatial relationships such as "under" and "inside of"; 3) It is a very effective way to fuse different features by first building separate modules for each of them, then adding their output logits before the final softmax layer. We show in ablation study that each factor can improve the performance to a non-trivial extent, and the model reaches optimal when all of them are combined.