Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntroducing MAPO: Momentum-Aided Gradient Descent Prompt Optimization
Paper and Code
Oct 25, 2024
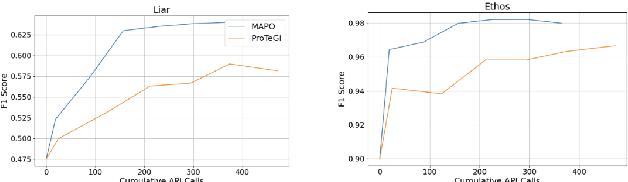

Momentum-Aided Prompt Optimization (MAPO) enhances the efficiency and efficacy of prompt optimization for Large Language Models (LLMs). Building on ProTeGi, MAPO uses positive natural language "gradients" and a momentum-based extension to refine prompts effectively. By tracking gradient history, MAPO avoids local minima and oscillations. It also utilizes beam search and an Upper Confidence Bound (UCB) algorithm for balanced candidate expansion and selection. Benchmark testing shows that MAPO achieves faster convergence time with fewer API calls and higher F1 scores than ProTeGi, proving it as a robust and scalable solution for automated prompt engineering in LLMs.
View paper on