 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteraction Networks: Using a Reinforcement Learner to train other Machine Learning algorithms
Paper and Code
Jun 15, 2020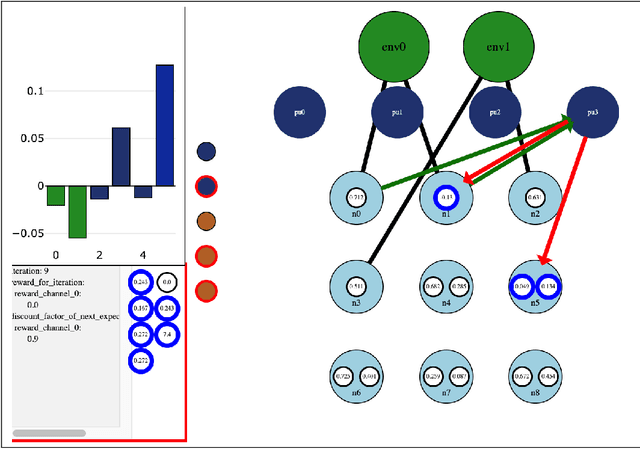
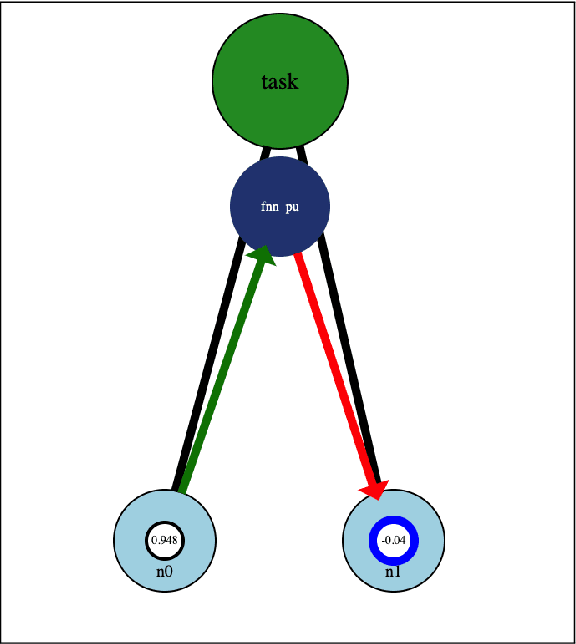
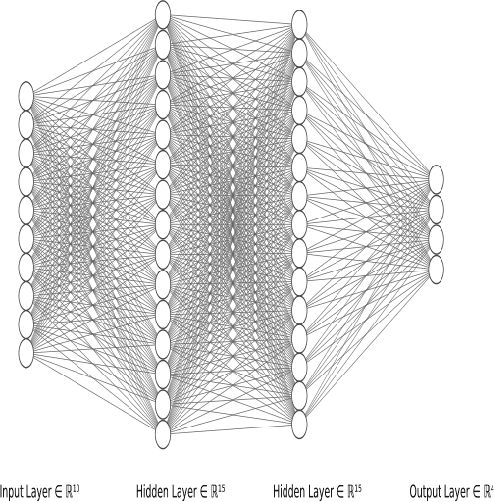
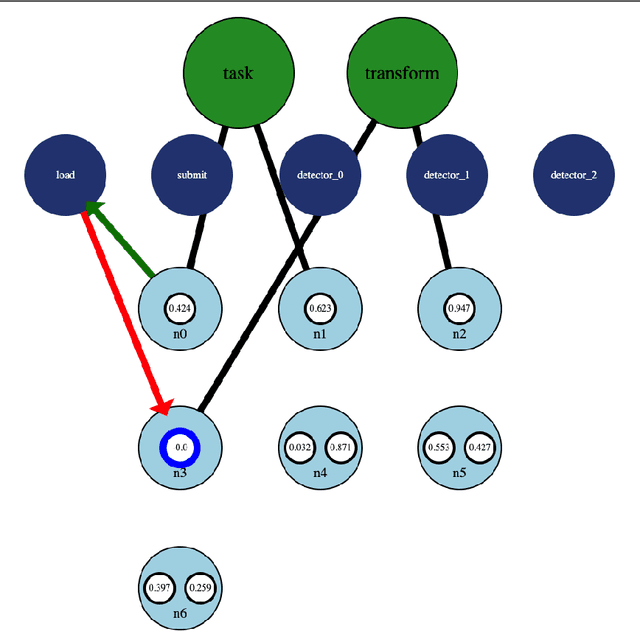
The wiring of neurons in the brain is more flexible than the wiring of connections in contemporary artificial neural networks. It is possible that this extra flexibility is important for efficient problem solving and learning. This paper introduces the Interaction Network. Interaction Networks aim to capture some of this extra flexibility. An Interaction Network consists of a collection of conventional neural networks, a set of memory locations, and a DQN or other reinforcement learner. The DQN decides when each of the neural networks is executed, and on what memory locations. In this way, the individual neural networks can be trained on different data, for different tasks. At the same time, the results of the individual networks influence the decision process of the reinforcement learner. This results in a feedback loop that allows the DQN to perform actions that improve its own decision-making. Any existing type of neural network can be reproduced in an Interaction Network in its entirety, with only a constant computational overhead. Interaction Networks can then introduce additional features to improve performance further. These make the algorithm more flexible and general, but at the expense of being harder to train. In this paper, thought experiments are used to explore how the additional abilities of Interaction Networks could be used to improve various existing types of neural networks. Several experiments have been run to prove that the concept is sound. These show that the basic idea works, but they also reveal a number of challenges that do not appear in conventional neural networks, which make Interaction Networks very hard to train. Further research needs to be done to alleviate these issues. A number of promising avenues of research to achieve this are outlined in this paper.