 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Protein Sequence and Expression Level to Analysis Molecular Characterization of Breast Cancer Subtypes
Paper and Code
Oct 02, 2024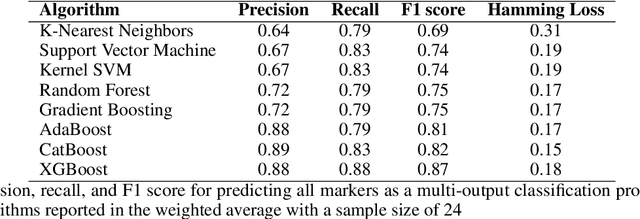

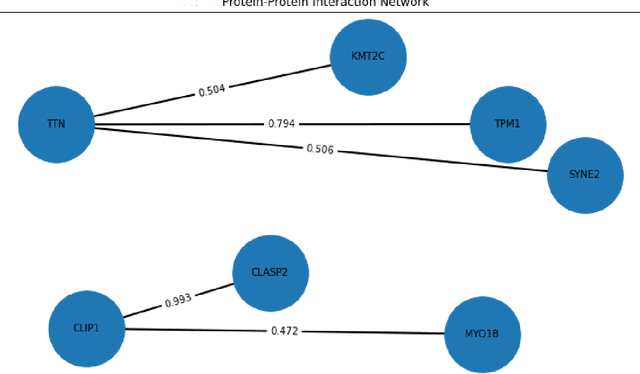
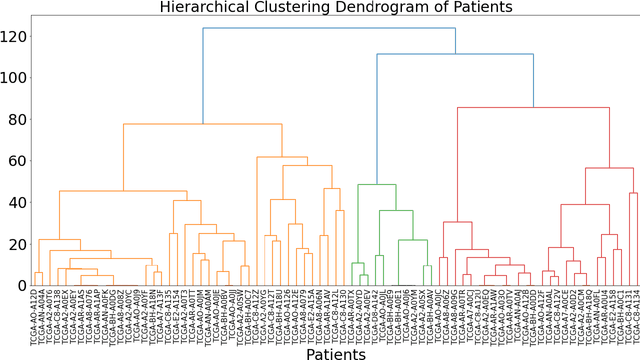
Breast cancer's complexity and variability pose significant challenges in understanding its progression and guiding effective treatment. This study aims to integrate protein sequence data with expression levels to improve the molecular characterization of breast cancer subtypes and predict clinical outcomes. Using ProtGPT2, a language model designed for protein sequences, we generated embeddings that capture the functional and structural properties of proteins sequence. These embeddings were integrated with protein expression level to form enriched biological representations, which were analyzed using machine learning methods like ensemble K-means for clustering and XGBoost for classification. Our approach enabled successful clustering of patients into biologically distinct groups and accurately predicted clinical outcomes such as survival and biomarkers status, achieving high performance metrics, notably an F1 score of 0.88 for survival and 0.87 for biomarkers status prediction. Analysis of feature importance highlighted key proteins like KMT2C, GCN1, and CLASP2, linked to hormone receptor and Human Epidermal Growth Factor Receptor 2 (HER2) expression, which play a role in tumor progression and patient outcomes, respectively. Furthermore, protein-protein interaction networks and correlation analyses revealed the interdependence of proteins that may influence breast cancer subtype behaviors. These findings suggest that integrating protein sequence and expression data provides valuable insights into tumor biology and has significant potential to enhance personalized treatment strategies in breast cancer care.