 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstruction Tuning with Human Curriculum
Paper and Code
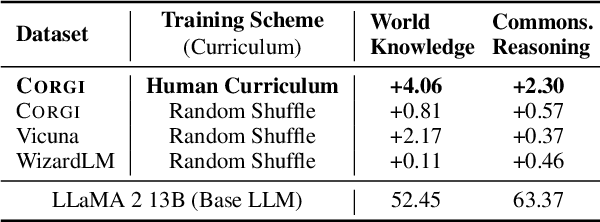
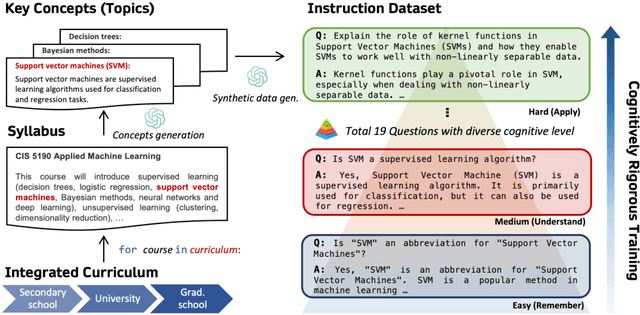
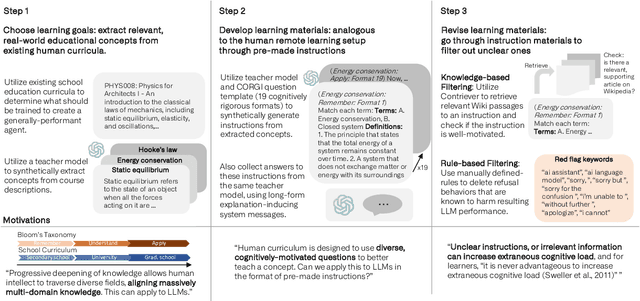
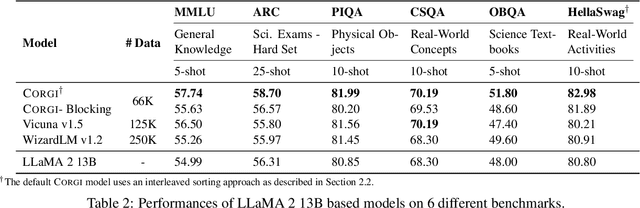
The dominant paradigm for instruction tuning is the random-shuffled training of maximally diverse instruction-response pairs. This paper explores the potential benefits of applying a structured cognitive learning approach to instruction tuning in contemporary large language models like ChatGPT and GPT-4. Unlike the previous conventional randomized instruction dataset, we propose a highly structured synthetic dataset that mimics the progressive and organized nature of human education. We curate our dataset by aligning it with educational frameworks, incorporating meta information including its topic and cognitive rigor level for each sample. Our dataset covers comprehensive fine-grained topics spanning diverse educational stages (from middle school to graduate school) with various questions for each topic to enhance conceptual depth using Bloom's taxonomy-a classification framework distinguishing various levels of human cognition for each concept. The results demonstrate that this cognitive rigorous training approach yields significant performance enhancements - +3.06 on the MMLU benchmark and an additional +1.28 on AI2 Reasoning Challenge (hard set) - compared to conventional randomized training, all while avoiding additional computational costs. This research highlights the potential of leveraging human learning principles to enhance the capabilities of language models in comprehending and responding to complex instructions and tasks.