 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformed Decision-Making through Advancements in Open Set Recognition and Unknown Sample Detection
Paper and Code
May 09, 2024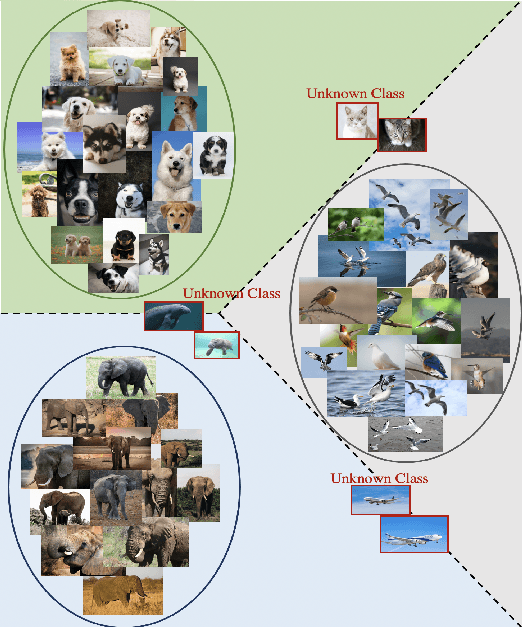
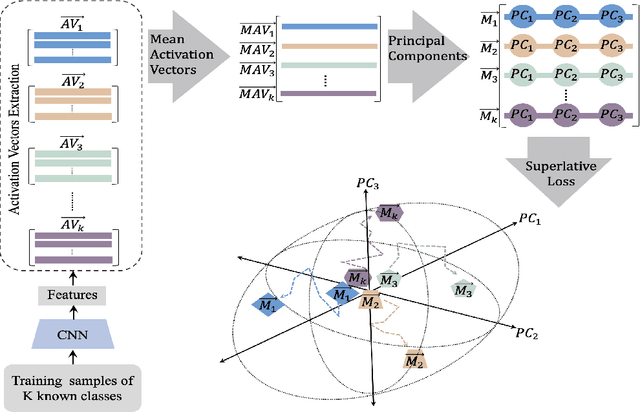
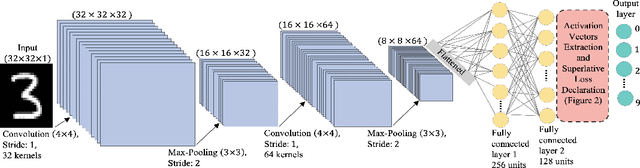
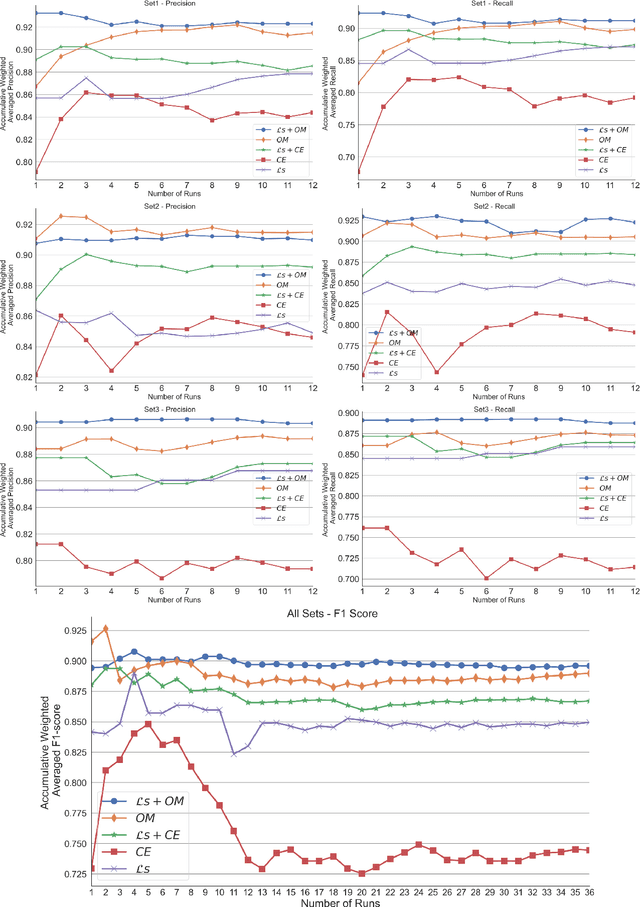
Machine learning-based techniques open up many opportunities and improvements to derive deeper and more practical insights from data that can help businesses make informed decisions. However, the majority of these techniques focus on the conventional closed-set scenario, in which the label spaces for the training and test sets are identical. Open set recognition (OSR) aims to bring classification tasks in a situation that is more like reality, which focuses on classifying the known classes as well as handling unknown classes effectively. In such an open-set problem the gathered samples in the training set cannot encompass all the classes and the system needs to identify unknown samples at test time. On the other hand, building an accurate and comprehensive model in a real dynamic environment presents a number of obstacles, because it is prohibitively expensive to train for every possible example of unknown items, and the model may fail when tested in testbeds. This study provides an algorithm exploring a new representation of feature space to improve classification in OSR tasks. The efficacy and efficiency of business processes and decision-making can be improved by integrating OSR, which offers more precise and insightful predictions of outcomes. We demonstrate the performance of the proposed method on three established datasets. The results indicate that the proposed model outperforms the baseline methods in accuracy and F1-score.