 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Targeted Molecule Generation through Language Model Fine-Tuning Via Reinforcement Learning
Paper and Code
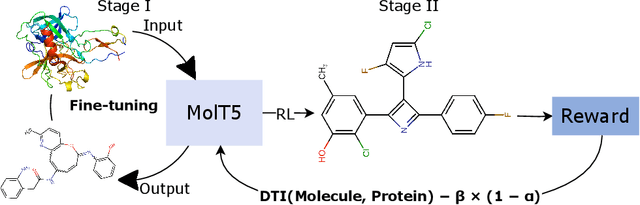

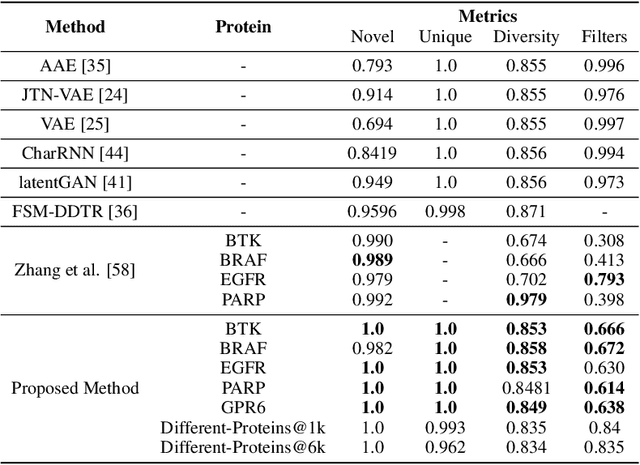
Developing new drugs is laborious and costly, demanding extensive time investment. In this study, we introduce an innovative de-novo drug design strategy, which harnesses the capabilities of language models to devise targeted drugs for specific proteins. Employing a Reinforcement Learning (RL) framework utilizing Proximal Policy Optimization (PPO), we refine the model to acquire a policy for generating drugs tailored to protein targets. Our method integrates a composite reward function, combining considerations of drug-target interaction and molecular validity. Following RL fine-tuning, our approach demonstrates promising outcomes, yielding notable improvements in molecular validity, interaction efficacy, and critical chemical properties, achieving 65.37 for Quantitative Estimation of Drug-likeness (QED), 321.55 for Molecular Weight (MW), and 4.47 for Octanol-Water Partition Coefficient (logP), respectively. Furthermore, out of the generated drugs, only 0.041\% do not exhibit novelty.